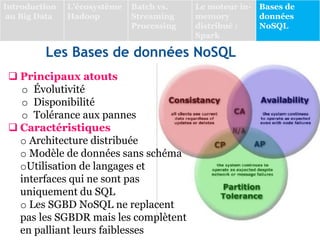
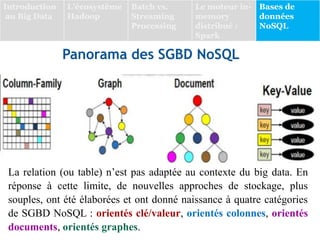
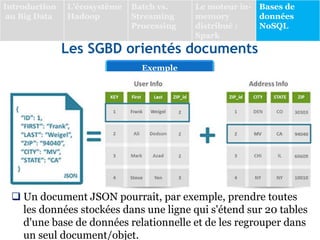
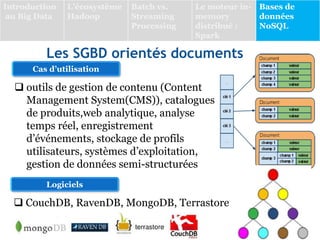
Le document présente une vue d'ensemble des bases de données NoSQL, qui émergent en réponse aux limitations des systèmes de gestion de bases de données relationnelles (SGBDR) face à la volumétrie et à la diversité des données dans un contexte de Big Data. Il décrit les différentes catégories de SGBD NoSQL, dont les bases orientées clé/valeur, documents, colonnes et graphes, en soulignant leurs caractéristiques, avantages et cas d'utilisation. Le document conclut avec des exemples de projets d'analyse de données, dont une étude sur l'épidémie de COVID-19 au Maroc.









































































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)


