NB: Ce documentdoit être complété par les notes du cours
Big Data
Elaboré par Dr. Souheyl
MALLAT
Souheyl.mallat@gmail.com
2023-2024
2.
Plan
• Chapitre 1: Introduction au Big Data
• Chapitre 2: MongoDB-Réplication et Sharding
• Chapitre 3 : Hadoop, MapReduce et le Big Data
• Chapitre 4 : Programmation MapReduce sous Hadoop
3.
3
Pourquoi ce cours?
• Selon LinkedIn, les compétences les plus recherchées
depuis plusieurs années sont :
1) Cloud and Distributed Computing (Hadoop,
Big Data)
2) Statistical Analysis and Data Mining (R, Data
Analysis)
• 10) Storage Systems and Management (SQL)
4.
4
Objectifs généraux
Cecours présente des outils et méthodes de traitement de gros volumes de données (Big
Data) au travers de la suite logicielle Hadoop.
Hadoop est un ensemble de services et d'applications permettant de stocker et
d'administrer des fichiers et des bases de données de très grande taille et de lancer des
programmes de calcul sur ces données.
Le principe est de répartir les données et les traitements sur un groupe de plusieurs
machines appelé amas (cluster).
Hadoop est utilisé par des entreprises comme Google, Facebook, Amazon, etc
Prérequis :
– Langage Java
– Langage Python de base
– Bases de données
– Systèmes d'exploitation
5.
5
• HDFS :un système de fichier distribué,
• MapReduce : API Java permettant l'écriture de programmes distribués
de recherche d'information,
• Spark : un outil concurrent de Hadoop pour exécuter des programmes,
• Cassandra : une base de données distribuée pouvant fonctionner avec
Spark,
• Pig : un outil permettant d'écrire des programmes destinés à
MapReduce avec un langage de script,
• HBase : une base de données orientée colonne, non SQL, qui s'appuie
sur HDFS,
• Hive : un SGBD appuyé sur HBase qui propose un langage de requête
ressemblant à SQL et générant des programmes MapReduce,
• ElasticSearch : une base de données distribuée.
Objectifs généraux
31
Des progrès initiéspar les géants du web
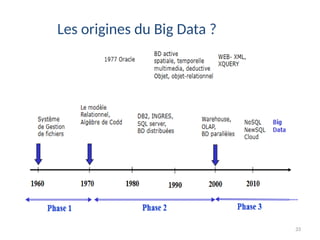
Les origines du Big Data ?
Pour bénéficier de ces ressources de stockage énorme, les géants du
web ont du développer pour leurs propres besoins de nouvelles
technologies notamment en matière de parallélisation des traitements
opérant des volumes de données se chiffrant en plusieurs centaines
de téraoctets
32.
32
• Des volumesqui relèvent du Big Data à partir du moment où
ces données ne peuvent plus être traitées en un temps
"raisonnables " ou "utiles« par des systèmes constitués d’un
seul nœud.
Les origines du Big Data ?
Question: Où se trouve la frontière du Big Data ?
Exemple: Si l’on doit traiter ou analyser un téraoctet de données,,
en quelques minutes il faudra impérativement recouvrir à une mise
en parallèle des traitements et du stockage sur plusieurs nœuds!
34
C’est quoi leBig Data ?
Définition1 : « data of a very large size, typically to the extent that its manipulation and
management present significant logistical challenges » Oxford English Dictionary,
«données de très grande taille, dont la manipulation et gestion présentent des enjeux du
point de vue logistiques »
Définition2 : « an all-encompassing term for any collection of data sets so large and
complex that it becomes difficult to process using on-hand data management tools or
traditional data processing applications » Wikipédia, « englobe tout terme pour décrire
toute collection de données tellement volumineuse et complexe qu’il devient difficile de
la traiter en utilisant des outils classiques de traitement d’applications »
Définition 3: « datasets whose size is beyond the ability of typical database software
tools to capture, store, manage, and analyze » McKinsey, 2011, « collections de données
dont la taille dépasse la capacité de capture, stockage, gestion et analyse des systèmes de
gestion de bases de données classiques»
35.
Big Data :Unpeu d’Histoire
C’est quoi le Big Data ?
36.
36
C’est quoi leBig Data ?
Ce qu’on retient ...
Volume des données,
Complexité,
Limites des outils classiques de gestion des données,
Passage à l’échelle
37.
37
C’est quoi leBig Data ?
• Explosion de la quantité de données,
Le partage de données,
Données partagées sur plusieurs serveurs
Réplication des données
Restitution des données
38.
38
C’est quoi leBig Data ?
• Explosion de la quantité de données,
• Le partage de données,
La recherche des données,
Données massives stockées quelques part,
Rechercher une donnée précise,
Il faut que la réponse soit optimisée:
en terme de recherche
en terme de résultat!
Comment parcourir ces données et en extraire des informations
facilement et rapidement?
39.
39
Traitement des fluxde données
Traitement des données énormes et dans un temps précis
Egalement coût de traitement moins cher !
40.
Big Data :Est-ce une innovation
C’est quoi le Big Data ?
42.
42
• Mégadonnées,
• Donnéesmassives.
C’est quoi le Big Data ?
Question: ? Le Big Data=le volume de données
Réponse: Faux !
Il n’y a pas que la volumétrie de données lorsqu’on parle de Big
Data!!
On parle Aussi de:
53
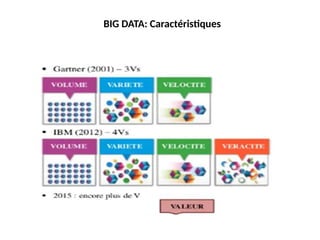
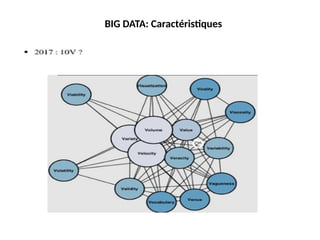
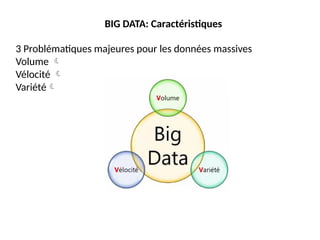
Les 5 Vde Big Data
Question: Comment déterminer les données qui méritent d’être stockées? :
Les données de Transactions? Logs? Métier? Utilisateur? Capteurs?
Médicales? Sociales?
Volume
- Téraoctets
- Enreg. / Archives
- Transactions
- Tables, fichiers
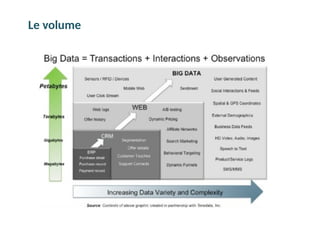
Le volume
Le prix de stockage des données a beaucoup diminué ces 30
dernières années: De $100,000 / Go (1980) à $0.10 / Go
(2013)
Les lieux de stockage fiables (comme des SAN: Storage Area
Network) ou réseaux de stockage peuvent être très coûteux !
Choisir de ne stocker que certaines données, jugées sensibles
Perte de données, pouvant être très utiles.
Problèmes:
▪ Comment stocker les données dans un endroit fiable, qui soit moins cher?
▪ Comment parcourir ces données et en extraire des informations facilement et rapidement?
Réponse: Aucune donnée n’est inutile.! Certaines n’ont juste pas encore servi!
54.
54
Des volumesqui relèvent du Big Data à partir du
moment où ces données ne peuvent plus être traitées
en un temps "raisonnables " ou "utiles« par des
systèmes constitués d’un seul nœud.
Le volume
56.
56
Les 5 Vde Big Data
Volume
- Téraoctets
- Enreg. / Archives
- Transactions
- Tables, fichiers
La variété (Variety)
Variété
- Structurées
- Non structurées
- Probabilistes
Pour un stockage dans des bases de données
ou dans des entrepôts de données, les
données doivent respecter un format
prédéfini!
Mais!
La plupart des données existantes sont non-structurées ou semi structurées,
Les données sont sous plusieurs formats et types (fichiers xml, json, txt, base de
données relationnelle, etc),
62
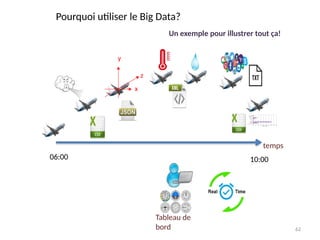
Pourquoi utiliser leBig Data?
Un exemple pour illustrer tout ça!
06:00 10:00
temps
Tableau de
bord
x
y
z
64.
64
C’est quoi leBig Data ?
Les 5 V de Big Data
La fréquence d’arrivée des données,
La vitesse de traitement des données,
Volume
- Téraoctets
- Enreg. / Archives
- Transactions
- Tables, fichiers
La vélocité /vitesse
(Velocity)
« Au cœur du Time to Market »
Variété
- Structurées
- Non structurées
- Probabilistes
Vélocité
- Batch
- Temps réel
- Processus
- Flot de données
Les données doivent être stockées à
l’arrivée, parfois même des
Teraoctets par jour!
Sinon, risque de les perdre!
Les entreprises se trouvent de plus en plus au milieu d’un flux continuel
de données
#2 Chapitre 1: Introduction à Big Data • Chapitre 2: Hadoop – Généralité – Architecture HDFS – Algorithme MapRduce – Installation et configuration Hadoop (TP inclus) • Chapitre 3: Utilisation de Hadoop – Manipulation de HDFS – Développement d’une application MapReduce – TP inclus • Chapitre 4: Spark – TP inclus • Chapitre 5: NoSQL • Chapitre 6: HBase, MangoDB – TP inclus
-----MongoDB - Réplication et Sharding
PLAN
Introduction MongoDB – Réplication et Sharding
Le Phénomène Big Data
Un peu d’Histoire
Notions
Les Problématiques des Big Data
Challenges & Problématiques
Stockage Traitement
Collecte
Lambda Architecture
Domaines de Recherche
#5 . Ce cours présente plusieurs outils de cette suite :
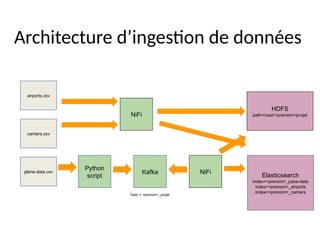
#6 Video 02/01/
https://hellichbucket.s3.eu-west-3.amazonaws.com/carriers.csv
https://hellichbucket.s3.eu-west-3.amazonaws.com/airports.csv
https://hellichbucket.s3.eu-west-3.amazonaws.com/plane-data.csv
#8 Tout a commencé quand l’Homme a voulu se faire entendre…
3. Au début, c’était un peu difficile…
4. Ensuite, un peu mieux
5. Il a inventé le livre pour tout noter
------------------------------------
http://www.enetcom.rnu.tn/fra/pages/325/Ing%C3%A9nierie-des-Donn%C3%A9es-et-Syst%C3%A8mes-D%C3%A9cisionnels
Description
Les data sciences, qui mélangent modélisation mathématique, statistique, informatique, visualisation et applications ont pour objectif de passer du stockage et de la diffusion de l’information à la création de connaissances.
Ce passage des données aux connaissances est porteur de nombreux défis qui requièrent une approche interdisciplinaire. Les data sciences s’appuient fortement sur le traitement statistique de l’information (statistiques mathématiques, statistiques numériques, apprentissage statistique ou machine learning). De l’analyse de données exploratoires aux techniques les plus sophistiquées d’inférence (modèles graphiques hiérarchiques, deep learning, machine à vecteurs de support), l’ensemble des méthodes statistiques des plus éprouvées aux plus modernes sont exploitées.
Le « Big Data » marque le début d’une transformation majeure, qui va affecter de façon profonde l’ensemble des secteurs (de l’e-commerce à la recherche scientifique en passant par la finance et la santé !).
#12 في البداية ، احتكرت مجموعة متميزة من المعلومات على الإنترنت
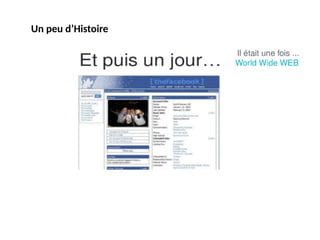
#14 Le World Wide Web, connu sous le nom de «WWW», a été lancé pour la première fois en 1991. Mais comme la technologie a avancé, de nouvelles versions sous forme de Web 2.0 et Web 3.0 ont été apparue. Web 2.0 et Web 3.0 sont évidemment considérés comme plus avancés et faciles à utiliser par rapport au Web 1.0.
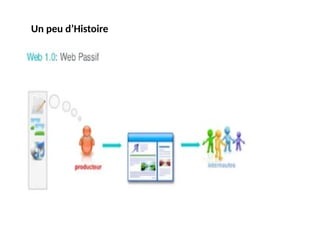
#15 Web 1.0
Web 1.0 est simplement un portail d’informations où les utilisateurs reçoivent passivement des informations sans avoir la possibilité de publier des commentaires ou des réactions.
#16 Web 2.0
Le Web 2.0 encourage la participation, la collaboration et le partage d’informations. Youtube, Wiki, Flickr, Facebook, etc., sont des exemples d’applications Web 2.0.
#17 La maturité de bigdata conséquence de plusieurs dsciplines
#19
Web 3.0
Le Web 3.0 est un Web sémantique qui fait référence au futur. Dans le Web 3.0, les ordinateurs peuvent interpréter les informations comme des êtres humains et générer et distribuer intelligemment un contenu utile adapté aux besoins des utilisateurs.
Web 3.0 : scial, sémantique comme SNA(social network analysis)
#20 Multiitudes de devices connéctés par exemple les web services façades de tt objets pingable(caméra, capteur), le tracking par gps, etc
Autres disciplines : data managment-bd sql , no sql, datawareshing, BI
NLP
#21 Capacité de stockage infini, réparti et sécurisé, fragmentation/réplication
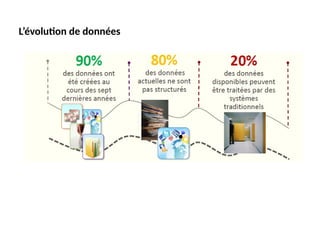
#22 L’évolution de données
Faits Big Data : Faits I Chaque jour, nous générons 2.5 trillions d’octets de données. I 90% des données dans le monde ont été créées au cours des deux dernières années. I Sources : - Capteurs utilisés pour collecter les informations climatiques. - Messages sur les médias sociaux. - Images numériques et vidéos publiées en ligne. - Enregistrements transactionnels d’achat en ligne. - Signaux GPS de téléphones mobiles. - ... I Chiffres clés - Plus de 2 milliards de vidéos regardées sur Youtube chaque jour et 220 milliards de recherche sur Google chaque mois. - 30 milliards de contenus statut, photo, vidéo, événement, etc. sont ajoutés sur Face- book par mois par plus de 600 millions d’utilisateurs actifs. - Le nombre d’appareils connectés à Internet a dépassé le nombre d’humains en 2008. - La compagnie de Social Games traite 1 Petabyte (1 million de GB) de données chaque jour. - Le marché du Big Data et des Big Analytics (ou broyage de données) pourraient représenter près de 250 milliards de dollars sur 4 ans.
#23 Challenges
défis
Big Data : Challenges Big Data : Challenges ? Réunir un grand volume de données variées pour trouver de nouvelles idées. ? Difficulté pour sauvegarder toutes ces données. ? Difficulté pour traiter ces données et les utiliser. ? Les données sont créées rapidement.
#26 Big Data : Intérêts Big Data : Intérêts I 1/3 - Chefs d’entreprise prennent fréquemment des décisions basées sur des informations en lesquelles ils n’ont pas confiance, ou qu’ils n’ont pas. I 1/2 - Chefs d’entreprise disent qu’ils n’ont pas accès aux informations dont ils ont besoin pour faire leur travail. I 83% - Des DSI (Directeurs des SI) citent : l’informatique décisionnelle et analytique comme faisant partie de leurs plans pour améliorer leur compétitivité. I 60% - Des PDG ont besoin d’améliorer la capture et la compréhension des informations pour prendre des décisions plus rapidement.
#27 Big Data : Sources (1) I Sources multiples : sites, Bases de Données, téléphones, serveurs : - Détecter les sentiments et les réactions des clients. Détecter les conditions critiques ou potentiellement mortelles dans les hôpitaux, et à temps pour intervenir. - Prédire des modèles météorologiques pour planifier l’usage optimal des éoliennes. - Prendre des décisions risquées basées sur des données transactionnelles en temps réel. - Identifier les criminels et les menaces à partir de vidéos, sons et flux de données. - ´Etudier les réactions des étudiants pendant un cours, prédire ceux qui vont réussir, d’après les statistiques et modèles réunis au long des années (domaine Big Data in Education).
Big Data : Sources Big Data : Sources (2) I Les données massives sont le résultat de la rencontre de trois éléments essentiels qui sont : - Internet. - Les réseaux sociaux. - Les appareils intelligents : les ordinateurs, les tablettes, les smartphones, les objets connectés... - L’Internet permet la transmission de l’information quelle que soit sa forme sur les appareils intelligents : Appareil intelligent : création de données. Utilisateur des réseaux sociaux : consommateur. Internet : vecteur de transmission
#31 Des progrès initiés par les géants du web ( Amazon, Apple, Facebook, Google, LinkedIn, Microsoft, Netflix, Twitter, etc)
Pour bénéficier de ces ressources de stockage énorme, les géants du web ont du développer pour leurs propres besoins de nouvelles technologies notamment en matière de parallélisation des traitements opérant des volumes de données se chiffrant en plusieurs centaines de téraoctets
#32 Selon cette définition() le BD n’est pas uniquement lié à la taille mais à la vitesse des traitements, Nous y reviendrons lorsque nous parlerons de 5 v!
#34 OED est un dictionnaire de référence pour la langue anglaise. .... C'est sous sa direction que collabore à ce projet le jeune J. R. R. Tolkien en 1919-1920.
----
https://fr.slideshare.net/AmalAbid1/cours-big-data-chap1
La notion de Big Data est un concept s’étant popularisé en 2012 pour traduire le fait que les entreprises sont confrontées à des volumes de données à traiter de plus en plus considérables et présentant un fort enjeux commercial et marketing.
• Ces Grosses Données en deviennent difficiles à travailler avec des outils classiques de gestion de base de données.
• Il s’agit donc d’un ensemble de technologies, d’architecture, d’outils et de procédures permettant à une organisation de très rapidement capter, traiter et analyser de larges quantités et contenus hétérogènes et changeants, et d’en extraire les informations pertinentes à un coût accessible.
------------------------
https://fr.slideshare.net/MinyarHidri/big-data-60723819
Qu’est-ce que le Big Data ? Définition Définition I Big Data : Exploration de très vastes ensembles de données pour obtenir des renseignements utilisables. I Le terme Big Data se réfère aux technologies qui permettent aux entreprises d’analyser rapidement un volume de données très important et d’obtenir une vue synoptique. I En mixant intégration de stockage, analyse prédictive et applications, le Big Data permet de gagner en temps, en efficacité et en qualité dans l’interpré- tation de données. I Les objectifs de ces solutions d’intégration et de traitements des données sont de traiter un volume très important de données aussi bien structurées que non structurées, se trouvant sur des terminaux variés (PC, smartphones, tablettes, objets communicants...), produites ou non en temps réel depuis n’importe quelle zone géographique dans le monde. ⇒ Le Big Data sera un outil majeur à la fois pour la prise de décisions et l’optimisation de la compétitivité au sein des entreprises ?
-----
Pour comprendre le «Big Data», vous devez d’abord connaître Qu’est-ce que les données?
Le Big Data c’est aussi des données mais avec une taille énorme. C’est un terme utilisé pour décrire une collection de données de grande taille et qui croît de façon exponentielle avec le temps.
En bref, ces données sont si volumineuses et complexes qu’aucun des outils traditionnels de gestion des données n’est capable de les stocker ou de les traiter efficacement.
Les données sont une combinaison de données structurées, semi-structurées et non structurées collectées par des organisations qui sont extraites pour des informations et utilisées dans des projets d’apprentissage automatique, de modélisation prédictive et d’autres applications d’analyse avancées.
Le domaine du Big Data regorge cependant de nombreux métiers tendance.
** Big Data - Pourquoi? ● Augmentation exponentielle de la quantité de données non structurées ○ Email, chat, blog, web, musique, photo, vidéo, etc. ● Augmentation de la capacité de stockage et d’analyse ○ L’utilisation de plusieurs machines en parallèle devient accessible ● Les technologies existantes ne sont pas conçues pour ingérer ces données ○ Base de données relationnelles (tabulaires), mainframes, tableurs (Excel), etc. ● De “nouvelles” technologies et techniques d’analyse sont nécessaires ○ “Google File System” - Google 2003 ○ “MapReduce: Simplified Data Processing on Large Clusters” - Google, 2004 ○ Hadoop: circa 2006 ● D’où le“Big Data”: pas strictement plus de data...
#35 https://fr.slideshare.net/LiliaSfaxi/thinking-big-big-data-principes-et-architecture
--------------------------------
raisonnable, il est nécessaire de paralléliser et de distribuer les traitements sur un grand nombre
de machines. Mais les machines étant des noeuds de données à base de PC standards reliés par un
réseau standard, pas des noeuds de calculs interconnectés par des réseaux très performants, il est
préférable d’adopter un schéma de parallélisation maximisant les traitements locaux, et recouvrant
les calculs et les communications.
Dans le cas du Map-Reduce d’Hadoop, il n’y a pas de communications entre les tâches Map,
ni entre les tâches Reduce, qui sont donc des tâches de calculs locaux. De plus l’étape de Shuffle
& Sort entraîne beaucoup de communications mais en partie recouvertes par les tâches Map et par
la réorganisation des données en entrée de chaque tâche Reduce, grace au pipelining d’Hadoop.
Pipeliner les traitements et les communications. Pour des raisons de performances il est souhaitable
de recouvrir les communications avec les calculs des tâches amont et aval, quand cela est
possible, afin de masquer les coûts de communication. Le mécanisme de Map-Reduce d’Hadoop
le fait en pipelinant une partie des traitements et les communications.
Rendre simples les développements applicatifs. Au final, l’architecture logicielle distribuée obtenue
(chaîne de Map-Reduce) est complexe, mais doit être exploitée par des data scientists et non
pas par des spécialistes du calcul parallèle. Dans cette optique plusieurs environnements logiciels,
comme Hadoop, Spark, MongoDB. . . permettent à des data scientists d’injecter facilement leurs
codes Map et Reduce dans une architecture logicielle qui prend déjà en charge tous les aspects
d’informatique distribuée.
#36
--------------------
Le Big Data répond donc à un double objectif :
assurer le passage à l'échelle (ou scalabilité), c'est-à-dire :
paralléliser les traitements informatiques (parallel computing) et les distribuer sur plusieurs machines (clustering) ;
stocker les données massives ;
manipuler les données en masse, c'est-à-dire :
exploiter ces grandes masses de données (statistiques, analyse prédictive et apprentissage automatique) ;
traiter et préparer les données et orchestrer les traitements (ETL, data pipeline et système de gestion de workflow).
#39 Cad aujourd’hui si on traite des flux des D, donc le Big data nous permet de taiter des D énormes et dans… egalement..
#40 Le traitement massivement parallèle (MPP, Massively Parallel Processing) désigne l'exécution coordonnée d'un programme par plusieurs processeurs focalisés .
Big Data : Est-ce une innovation ? I L’explosion des volumes des données nécessite une innovation en terme de : - Acceleration matérielle : Abandon des disques durs au profit des mémoires dy- namiques DRAM (Dynamic Random Access Memory : mémoire vive dynamique) ou flash. ⇒ Meilleur benefice des processeurs multicœurs. I Bases de données d’analyse massivement parallèle (MPP) : Ces bases de données conformes SQL sont conc¸ues pour répartir le traitement des données sur plusieurs machines. I Modèle Map-Reduce, Hadoop et autres approches NoSQL : Ces approches permettent d’accéder aux données via des langages de programmation sans utiliser les interfaces basées sur SQL et permettent de répartir les données sur plusieurs machines distinctes
#42 Quand on parle de BigData on entend parler certainement de ..
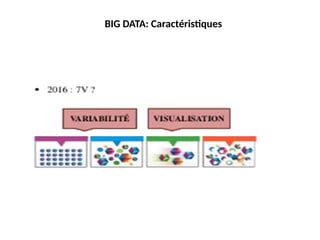
#43 BIG DATA: Caractéristiques • COUVERTURE DE CINQ DIMENSIONS - 7Vs
#46 BIG DATA: Caractéristiques • COUVERTURE DE CINQ DIMENSIONS - 5Vs (1/2) Gartner (2001) – 3Vs IBM (2012) – 4Vs 2015 : encore plus de V VOLUME VARIETE VELOCITE VOLUME VARIETE VELOCITE VERACITE VALEUR
Volume stockage
Vélocité -Traitement
Variétécollecte
#47 Volume
Le nom Big Data lui-même contient le terme “énorme”. La taille des données joue un rôle très crucial dans la détermination de la valeur(insights) des données.
De plus, le fait de savoir si une donnée particulière peut réellement être considérée comme un Big Data ou non dépend du volume de données.
Par conséquent, le «volume» est une caractéristique qui doit être prise en compte lors du traitement des mégadonnées.
Le prochain aspect est sa variété.
---
https://fr.slideshare.net/LiliaSfaxi/thinking-big-48033518
#50 Données d’administration pub=Données ouvertes
RFID veut dire Radio Fréquence Identification, ou plus simplement radio-identification en français. Cette technologie permet de lire, sauvegarder et collecter ...
#52 -Un ERP (Enterprise Resource Planning) ou encore parfois appelé PGI (Progiciel de Gestion Intégré) est un système d'information qui permet de gérer et suivre au quotidien, l'ensemble des informations et des services opérationnels d'une entreprise.
- Gestion de la Relation Client en Français, c'est l'art de créer, développer et entretenir une relation privilégiée avec chacun de vos contacts.
#53 La solution été de choisir de ne stocker que.. Et la perte
----
Volume (1/2) • Croissance sans cesse des données à gérer de tout type, souvent en teraoctets voir en petaoctets. • Chaque jour, 2.5 trillions d’octets de données sont générées. • 90% des données créées dans le monde l’ont été au cours des 2 dernières années (2014). • Prévision d’une croissance de 800% des quantités de données à traiter d’ici à 5 ans.
#56 Les données sont sous plusieurs formats et types (fichiers xml, json, txt, base de données relationnelle, etc),
Certaines données peuvent paraître obsolètes, mais sont utiles pour certaines décisions.
Variété
La variété fait référence à des sources hétérogènes et à la nature des données, à la fois structurées et non structurées.
Auparavant, les feuilles de calcul et les bases de données étaient les seules sources de données prises en compte par la plupart des applications. De nos jours, les données sous forme de courriels, photos, vidéos, appareils de surveillance, PDF, audio, etc. sont également prises en compte dans les applications d’analyse.
Cette variété de données non structurées pose certains problèmes pour le stockage, l’extraction et l’analyse des données.
---
Un exemple typique d’utilisation de données hétéroclites est celui d’un croisement entre des données contenues dans un CRM (gestionnaire de la relation client), des données géolocalisation, des données extraites d’un réseau social qui collectivement permettont d’enrichir un profil utilisateur avec des informations à caractère affectif très souvent corrélées au déclenchement d’un acte d’achat!
-----------------------
Variété • Traitement des données sous forme structurée (bases de données structurée, feuilles de calcul venant de tableur, …) et non structurée (textes, sons, images, vidéos, données de capteurs, fichiers journaux, medias sociaux, signaux,…) qui doivent faire l’objet d’une analyse collective. • Diversité des données Variété
#57 https://www.digitalwallonia.be/fr/publications/big-data-la-revolution-des-donnees
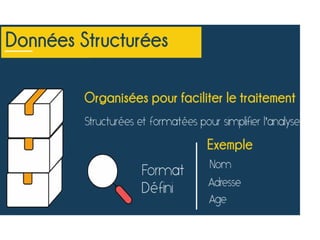
On peut d'autre part envisager deux grandes catégories de données:
les données structurées. Ce sont les données que l'on peut facilement organiser par rangées et colonnes, et qui sont traditionnellement gérées dans des bases de données. Il s'agit notamment des données liées au fonctionnement habituel des entreprises et organisations (stocks, comptabilité, finances, ressources humaines, statistiques, études scientifiques, ...)
les données non structurées. Déjà présentes sous la forme de la production bureautique non organisée, ces données se multiplient de manière exponentielle et incontrôlable avec les plateformes de crowdsourcing, le mobile et l'Internet des objets. Par leur volume, leur vitesse d'acquisition et la variété de leurs formats, elles nécessitent de nouveaux outils pour leur stockage, leur traitement et leur analyse. C'est à leur développement que correspond la naissance du Big Data.
Les 3, 4, 5, ... 6 V du Bi
#58 Variété (2) Données structurées versus Données non structurées I Données structurées : Données que l’on peut clairement codifier et identifier. I Les données d’un tableur sont typiquement des données structurées. I On peut comprendre leurs significations en croisant les titres de la ligne et colonne dans laquelle se trouent les données. ⇒ Les systèmes d’analyse algorithmique ont depuis toujours été développés pour traiter ce type de données. I Données non structurées : Données qui ne répondent pas à un codage qui per- met d’en tirer de l’infor- mation. I C’est en analysant les contenus des messages que l’on déduit l’informa- tion : fichiers texte, au- dio, vidéo, etc. que l’on peut clairement codifier et identifier.
#61 Donc les entrprise dispose les differents types de données qui pourront passer par un pipeline qui tiendra la possibilité de le traiter pour faire tte sorte d’anayse
#62 JavaScript Object Notation (JSON) est un format de données textuelles dérivé de la notation des objets du langage JavaScript. Il permet de représenter de l’information structurée comme le permet XML par exemple
#63 Vitesse ou Vélocité
Le terme «vitesse» fait référence à la vitesse de génération des données. La rapidité avec laquelle les données sont générées et traitées.
La vélocité du Big Data traite de la vitesse à laquelle les données circulent à partir de sources telles que les processus métier, les journaux d’applications, les réseaux et les sites de médias sociaux, les capteurs, les appareils mobiles, etc. Le flux de données est massif et continu.
#64 Les entreprises se trouvent de plus en plus au milieu d’un flux continuel de données, qu’il soit interne ou externe!
Exemple 2:
▪ Il ne suffit pas de savoir quel article un client a acheté ou réservé
▪ Si on sait que vous avez passé plus de 5mn à consulter un article dans une boutique d’achat en ligne, il est possible de vous envoyer un email dès que cet article est soldé.