Téléchargé 25 fois



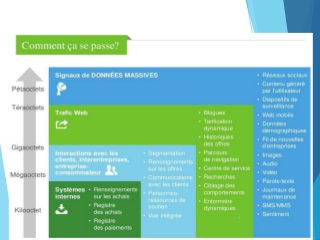












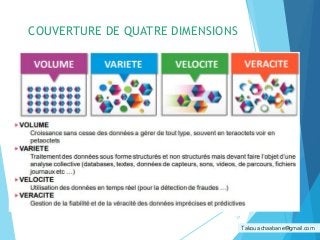








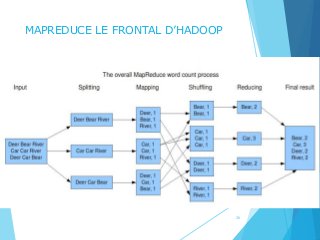


Le document traite de l'évolution du big data, son impact sur le monde numérique et les défis associés à la gestion des données massives. Il présente les caractéristiques du big data à travers les concepts des 4V et 8V, ainsi que les technologies de stockage et de traitement, notamment Hadoop et ses fonctions MapReduce. Les perspectives d'utilisation des données sont également explorées, mettant en lumière leur importance dans divers domaines tels que l'analyse politique et le marketing.



























