Téléchargé 10 fois





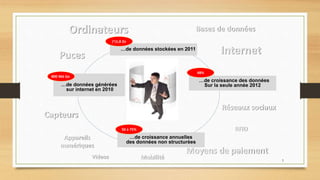


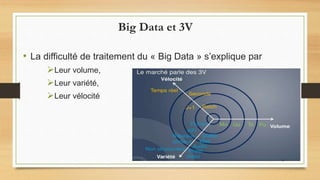

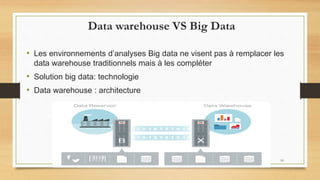













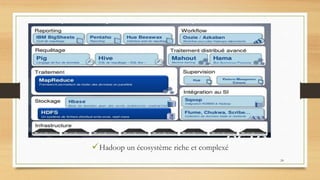








Le document traite du big data, défini comme de grands ensembles de données difficiles à gérer avec des outils traditionnels, et explique ses caractéristiques essentielles telles que le volume, la variété et la vélocité. Il aborde également les différences entre les systèmes de data warehouse et les environnements de big data, ainsi que des exemples d'utilisation dans divers domaines, en particulier à travers l'analyse de données générées par les réseaux sociaux et les appareils mobiles. Enfin, il souligne l'importance croissante du big data pour optimiser l'efficacité et la compétitivité des organisations.
































































