Téléchargé 170 fois




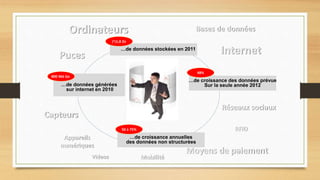


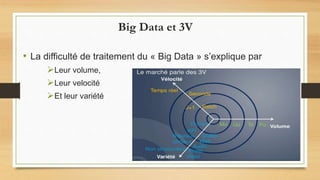

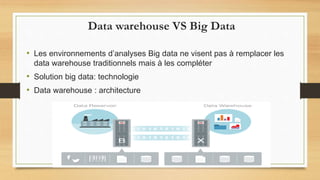





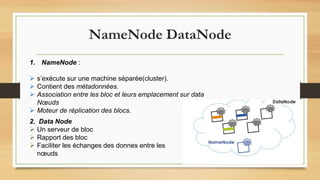







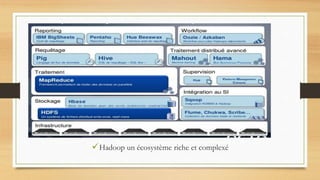








Le document traite du big data, défini comme des ensembles de données si volumineux qu'ils nécessitent des technologies spécifiques pour leur gestion. Il aborde les défis liés aux 3V du big data : volume, variété et velocité, ainsi que l'utilisation de frameworks comme Hadoop et des outils comme MapReduce pour le traitement des données. Enfin, il souligne l'importance croissante des données générées par les smartphones et les défis liés à leur stockage et utilisation.















































