



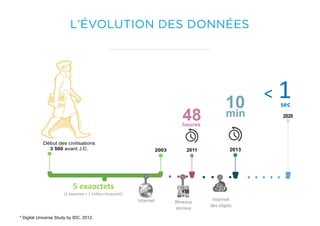

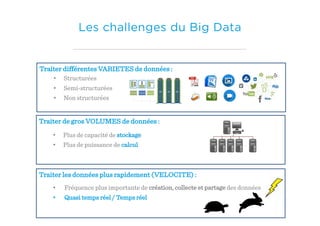
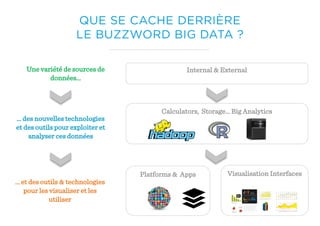









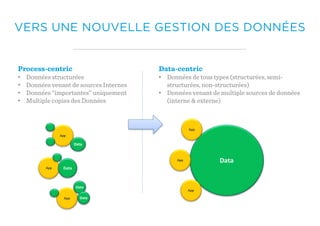
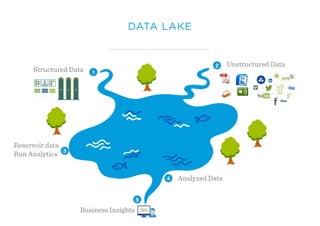
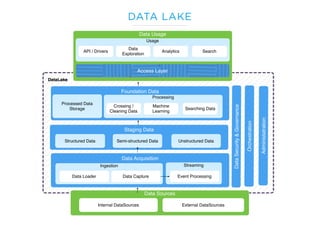


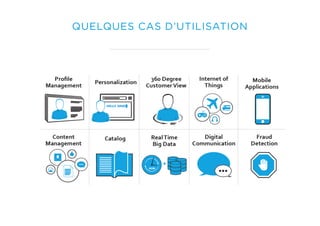




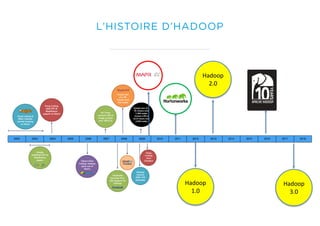




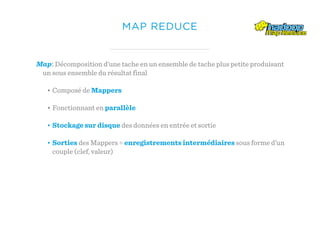
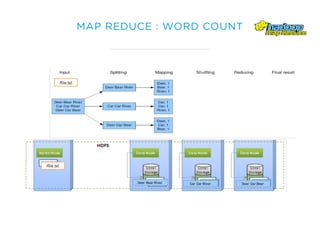

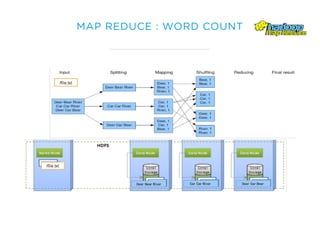

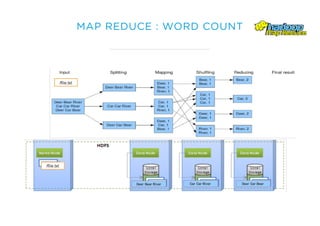
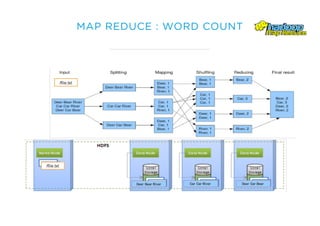
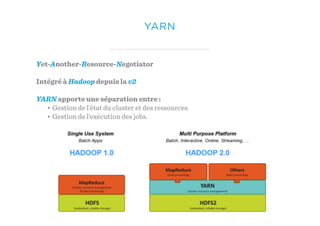


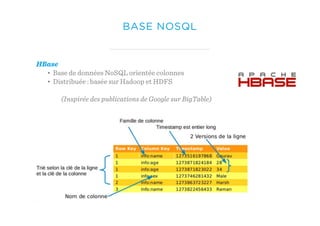


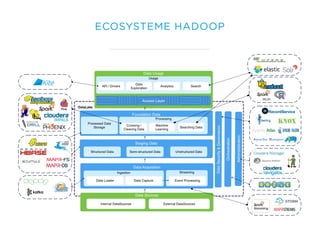

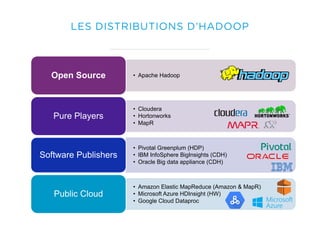
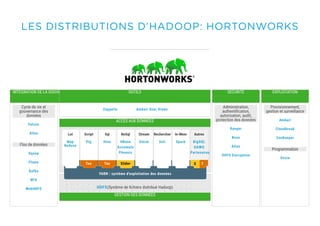
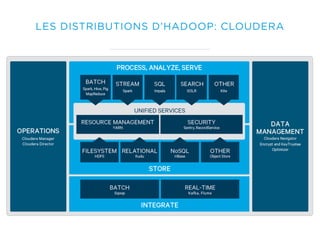



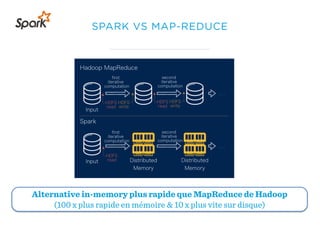
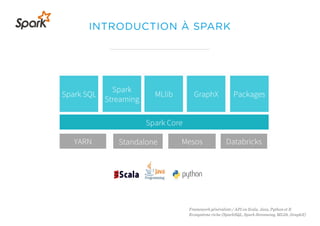

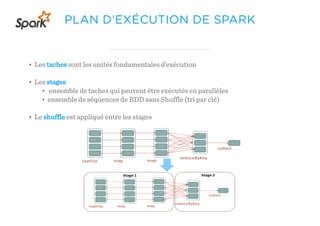
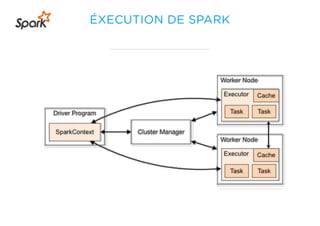



Le document présente un aperçu du big data et de son écosystème, mettant en lumière des technologies comme Hadoop et Spark, ainsi que des concepts clés tels que le traitement des données et les data lakes. Il aborde également les défis du big data, les différentes sources de données, et les cas d'utilisation, tout en soulignant l'importance de la visualisation et des outils d'analyse. Enfin, il conclut sur l'évolution de ces technologies et les nouvelles tendances dans la gestion des données.















































