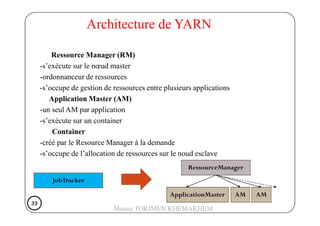
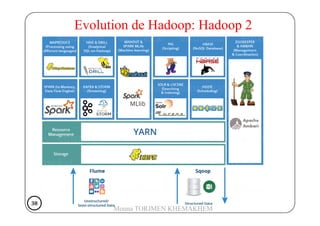
Le document traite de Hadoop, un framework open source pour le stockage et le traitement de grandes quantités de données, développé par Doug Cutting en 2004. Il présente l'architecture de Hadoop, y compris HDFS pour le stockage distribué et MapReduce pour le traitement des données, ainsi que son historique et ses évolutions, notamment l'introduction de YARN pour la gestion des ressources. Les sections abordent également les fonctionnement des composants comme le Namenode, Datanode, et les commandes essentielles à utiliser dans HDFS.

























![• But: compter le nombre de visiteurs sur chacune des pages d'un
site Internet.
• Données: des fichiers de logs sous la forme suivante:
/index.html [19/Oct/2013:18:45:03 +0200]
/contact.html [19/Oct/2013:18:46:15 +0200]
MapReduce-Exemple 2
• MAP/REDUCE: (clef, valeur)= (URL, 1)
/contact.html [19/Oct/2013:18:46:15 +0200]
/news.php?id=5 [24/Oct/2013:18:13:02 +0200]
/news.php?id=4 [24/Oct/2013:18:13:12 +0200]
/news.php?id=18 [24/Oct/2013:18:14:31 +0200]
...etc...
26262626
Mouna TORJMEN KHEMAKHEM](https://image.slidesharecdn.com/chapitre2-hadoop-180327112442/85/Chapitre-2-hadoop-26-320.jpg)