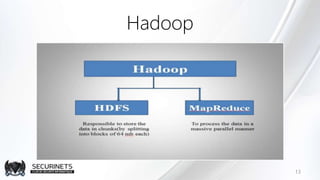
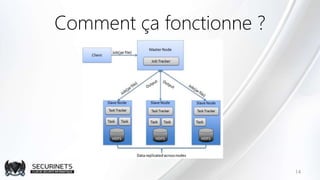
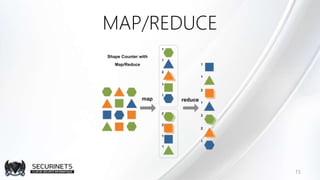
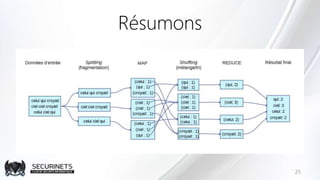
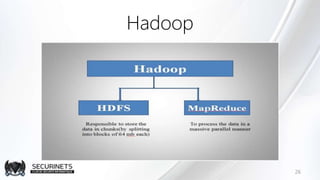
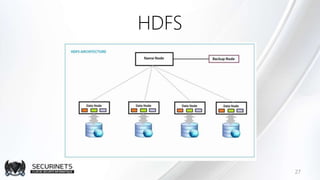
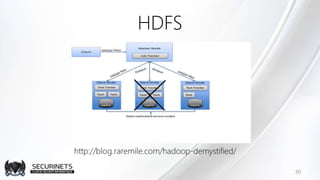
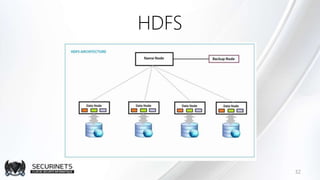
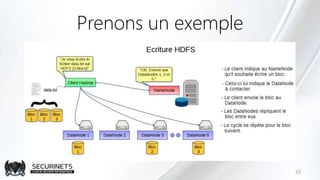
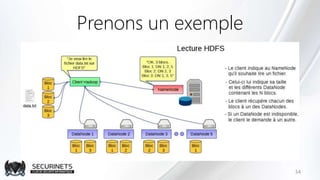
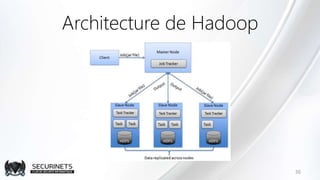
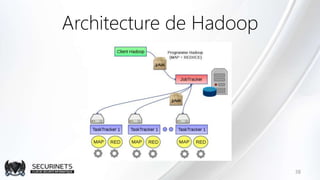
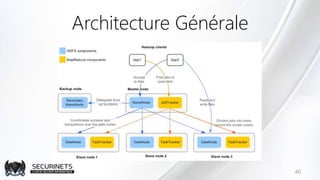
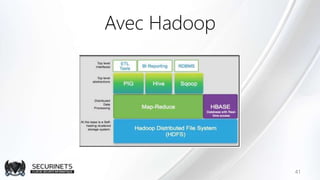
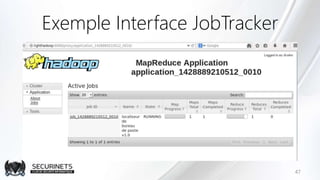
Hadoop est un framework de calcul distribué créé par Doug Cutting en 2002, permettant de traiter de grandes quantités de données en exploitant des clusters de machines. Il repose sur des concepts comme le système de fichiers distribué HDFS et le modèle de programmation MapReduce, qui permet de découper les tâches en unités parallélisables. Son succès est dû à sa nature open source, sa facilité d'utilisation et sa capacité à s'adapter à des infrastructures hétérogènes tout en offrant une tolérance aux pannes.