Téléchargé 111 fois





![Réfléchissons au
problème de taille
• On veut trouver les 5 mots les plus fréquents dans
une collection de textes.
• Faisons un petit algo en pseudo-code:
def wordCount(text):
counts = defaultdict(int)
for word in text:
counts[word] += 1
5](https://image.slidesharecdn.com/mapreduce-130821170205-phpapp01/85/MapReduce-Traitement-de-donnees-distribue-a-grande-echelle-simplifie-5-320.jpg)












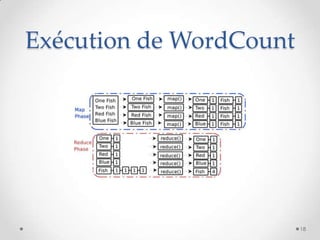
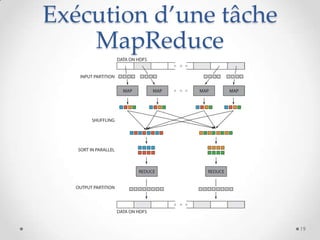

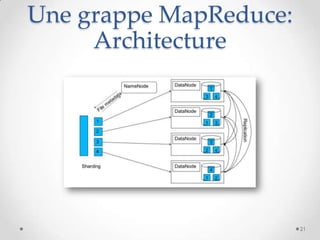











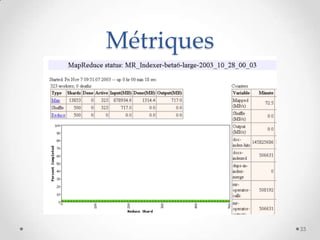



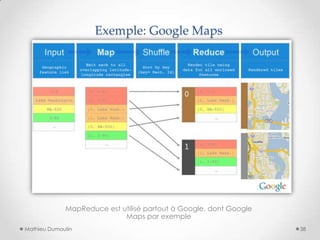






Le document présente MapReduce, un modèle de programmation développé par Google pour le traitement distribué de grandes quantités de données à l'échelle. Il traite des défis rencontrés par les grandes entreprises en matière de traitement de données et propose des solutions pour gérer les pannes matérielles. MapReduce simplifie le développement d'applications robustes et efficaces, permettant une utilisation optimale de l'infrastructure à faible coût.











































































