Téléchargé 38 fois



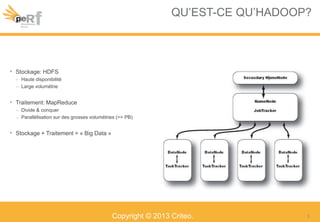

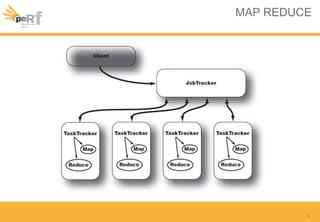
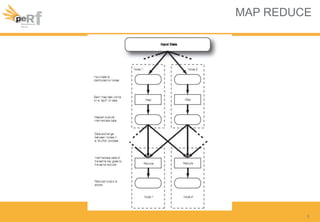
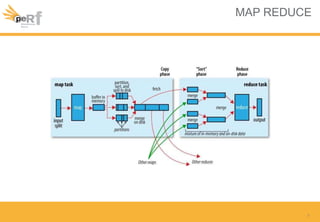
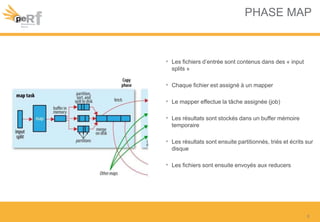




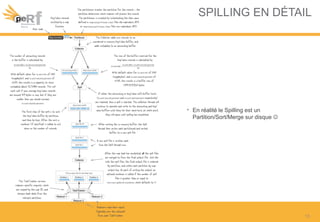

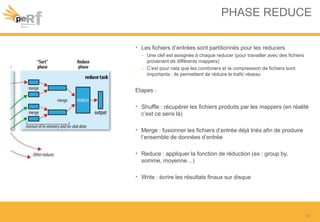
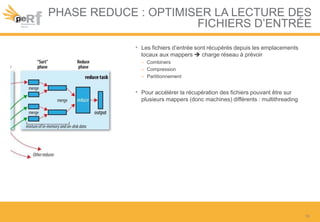

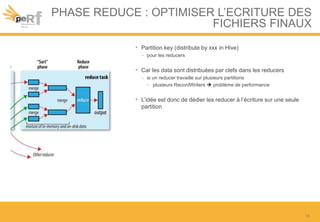


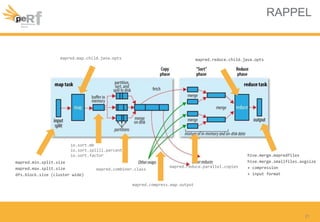
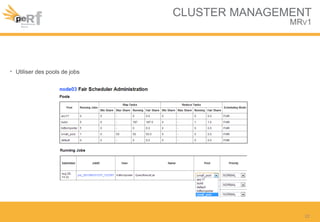
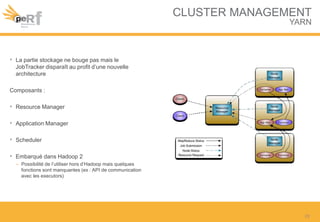
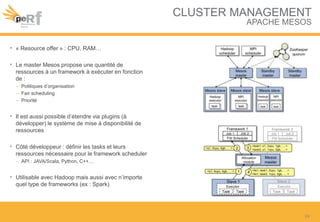



Le document présente une série de meilleures pratiques pour optimiser les performances d'Hadoop, en mettant l'accent sur la configuration des clusters, l'utilisation de MapReduce, et des techniques d'optimisation pour le traitement des données. Il aborde également des sujets comme la gestion de la mémoire, la gestion de ressources avec YARN et Apache Mesos, ainsi que l'importance du monitorage pour affiner les performances. Enfin, des conseils pratiques sont donnés pour décider quand utiliser Hadoop en fonction des volumes de données.


































































