
Contenu connexe
Tendances
Tendances (20)
Similaire à Hadoop
Similaire à Hadoop (20)
Hadoop
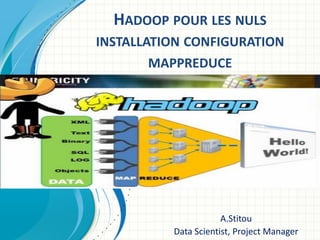
- 1. HADOOP POUR LES NULS INSTALLATION CONFIGURATION MAPPREDUCE A.Stitou Data Scientist, Project Manager
- 2. sommaire • Introduction • Appercu hadoop • Caractéristique Hadoop • Les distributions hadoop • Les domaines d’application d’Hadoop • Fonctionnement de hadoop • HDFS Schéma de stockage des blocs • HDFS: le namenode • HDFS: le Datanode • HDFS:Ecriture/Lecture d’un fichier • HDFS: Tolérance aux fautes • Fonctionnement d’hadoop, HDFS • Hadoop Mapreduce • Hadoop Mapreduce • Développement de programmes MapReduce • Installation • Configuration • Lancement de Hadoop • Interface web d’hadoop
- 3. Introduction • Hadoop est un framework 100% open source,écrit en Java et géré par la fondation Apache • Hadoop est capable de stocker et traiter de manière efficace un grand nombre de donnés, en reliant plusieurs serveurs banalisés entre eux pour travailler en parallèle. • Hadoop est utilisé par des entreprises ayant de très fortes volumétries de données à traiter. Parmi elles, des géants du web comme Facebook, Twitter, LinkedIn, ou encore les géants de l’e-commerce à l’instar de eBay et Amazon
- 4. Appercu hadoop • Plate forme Map-Reduce open-source écrite en java(Doug Cutting 2009 projet de la fondation apache • Un systéme de fichier distribué (HDFS) • Un ordonnenceur du programmes Map-Reduce • Une API Map-Reduce en Java, Python C++,… • Une interface utilisateur • Une interface administrateur
- 5. Caractéristique Hadoop • Economique : Permet aux entreprises de libérer toute la valeur de leurs données en utilisant des serveurs peu onéreux. • Flexible : Hadoop permet de stocker de manière extensible tous types de données. grâce à son système de fichier HTDFS Les utilisateurs peuvent transférer leurs données vers Hadoop sans avoir besoin de les reformater. • Tolère les pannes: les données sont répliquées à travers le cluster afin qu’elles soient facilement récupérables suite à une défaillance du disque, du nœud ou du bloc
- 6. Les distributions hadoop Quatre solutions leaders sur le marché se partagent Hadoop : Cloudera, Hortonworks, MapR, Amazon Elastic Map Reduce (EMR). • Cloudera est une plateforme Big Data mature aujourd’hui. Elle est composée de 2 éditions : l’offre express et l’offre entreprise (la version commerciale). Son grand atout reste son interface unifiée de gestion. • Hortonworks est la solution dont vous aurez besoin pour bénéficier d’un support d’entreprise tout en bénéficiant d’une technologie 100% open source. • MapR : son système de fichiers MapR-Fdécuple la vitesse d’écriture et de lecture des données. • Amazon Elastic MapReduce (EMR), Amazon offre même une solution hébergée, pré-configurée dans son cloud
- 7. Les domaines d’application d’Hadoop • Dans le domaine de la gestion de clientèle (Anticipation des désabonnement) • Dans le domaine de la publicité (Ciblage de la clientèle) • Dans le domaine de la lutte contre la fraude • Etc….
- 8. Fonctionnement de hadoop • Hadoop fonctionne sur le principe des grilles de calcul consistant à répartir l’exécution d’un traitement intensif de données sur plusieurs noeuds ou grappes de serveurs. • Les machines sont regroupés par rack
- 9. Fonctionnement de hadoop Hadoop est principalement constitué de deux composants : • Le système de gestion de fichiers distribué, HDFS. • Le framework MapReduce (version 1 Hadoop)/YARN (version 2 de Hadoop L’écosystème Hadoop comprend de nombreux autres outils couvrant le stockage et la répartition des données, les traitements distribués, l’entrepôt de données, le workflow…….
- 10. HDFS • Optimisé pour stocker de très gros fichiers • Les fichiers sont divisés en blocs(taille 128 Mo) • Une architecture maitre-esclave • Le maitre HDFS:le Namenode • Les esclaves de HDFS: les DataNoeuds • Les blocks sont stockées sur datanodes • Chaque block est répliqué sur différents datanodes(3 par défaut) Conçu pour un mode 1 écriture pour plusieurs lectures • Lecture séquentielle • Écriture en mode appendy-only
- 11. HDFS Schéma de stockage des blocs
- 12. HDFS: le namenode • Responsable de la distribution et de la réplication des blocs • Serveurs d’information du HDFS pour le client HDFS • Stockage et gère les méta-données • Liste des blocs pour chaque bloc • Liste des fichiers • Liste des datanodes pour chaque bloc • Attributs des fichiers(ex: Nom,date de création, facteur de réplication) • Log toute méta-donnés et toutes transaction sur un support persistant • Lecture/écritures • Création/suppression Démare à partir d’une image de HDFS(fSimage) • La capacité mémoire du Namenode décidera du nombre de blocs que l on peut avoir dans le HDFS
- 13. HDFS: le Datanode • Stocke des blocks de données dans le systèmes de fichier local • Maintient des métadonnées sur blocks • Serveurs de bloc de données et de métadonnées pour le client HDFS • Heartbeat avec le Namenode – Message aller vers le Namenode indiquant • Son identité • Sa capacité totale, son espace restant – Message-retour depuis le Namenode • Des commandes(copie de blocs vers d d’autres Datanodes, invalidation, de blocs, etc) • En plus du heartbeat, informe régulièrement la Nameode des blocs qu il contient
- 15. HDFS:Ecriture/Lecture d’un fichier • Le client, récupère la liste de Datanodes sur lequel placer les différents réplicas, écrit le bloc sur le premier Datanode • Le premier Datanode transfère les données au prochain Datanode dans le pipeline • Quand tous les réplicats sont écrits, le client recommence la procédure pour le prochain bloc du fichier • Stratégie courante • Un réplica sur un autre rack • Un troisième réplica sur un rack d’un autre Datacenter • Les réplicas supplémentaires sont placés de façon aléatoires • Le client lit le plus proche réplicat
- 16. HDFS: Tolérance aux fautes Crasch du Datanode • Plus de hearbeat(detection par le namenode) • Réplication distribuée(robustesse de données) Crasch du Namenode • Sauvegarde des logs de transaction sur un support stable • Redémarrage sur la dernière image du HDFS et application des log de transaction(recouvrement)
- 17. Fonctionnement d’Hadoop, HDFS • Le programme Hadoop demande la création du fichier à HDFS, par le biais d’une instruction create(). • HDFS envoie une demande de création de fichier au NameNode, par le biais d’un appel de type RPC. • Le NameNode s’assure que le fichier n’existe pas et que le programme Hadoop disposes des droits nécessaires pour créer le fichier. Si tout se passe bien, le NameNode ajoute le nouveau fichier dans sa cartographie des données du cluster. Sinon, une exception IOException est générée • HDFS renvoie une instance de FSDataOutputStream au programme, ce qui lui permet d’accéder au fichier en écriture. • .
- 18. Fonctionnement d’Hadoop, HDFS • Les lignes envoyées à HDFS pour écriture dans le fichier sont découpées en paquets et stochées temporairemenr dans une file d’attente, qui est prise en charge par une instance de DataStreamer : – DataStreamer demande au NameNode les adresses de trois blocs sur trois DataNodes différents pour y stocker les données de la file d’attente. – Chaque fois qu’un paquet de données a été stocké avec succès sur un DataNode, un accusé de réception du paquet est envoyé à FSDataOutputStream. – DataStreamer pourrait demander au NameNode trois nouvelles adresses lorsqu’un groupe de trois blocs est plein. • Enfin, lorsque le dernier paquet a été écrit avec succès sur trois DataNodes différents, le programme Hadoop envoie close() à FSDataOutputStream.
- 19. Hadoop Mapreduce • MapReduce est un modèle de programmation conçu spécifiquement pour lire, traiter et écrire des volumes de données très importants. MapReduce consiste en deux fonctions map() et reduce(). • MapReduce implémente les fonctionnalités suivantes : – Parallélisation automatique des programmes Hadoop. – HDFS se charge de la répartition et de la réplication des données ; – Le maître divise le travail en jobs parallèles et les répartit – Le maître collecte les résultats et gère les pannes des noeuds. – Gestion transparente du mode distribué. – Tolérance aux pannes
- 20. Hadoop Mapreduce
- 21. Hadoop Mapreduce Jobtracker – Gere l’ensemble des ressources du systémes – Reçoit des jobs des clients – Ordonnance les différents tâches des jobs soumis – Assigne les taches au Tasktrackers – Réaffecte les taches défaillantes – Maintient des informations sur l’états d’avancement Un trasktracker Exécute les taches données par le jobtracker Exécution des taches dans une autre JVM(Child)
- 22. Développement de programmes MapReduce • Le programme WordCount un exemple très connu • un programme Hadoop comptant le nombre d’occurrences des différents mots composant un livre. • pour chaque mot w de la ligne en cours • on écrit dans un fichier en sortie le couple <w, 1>, 1 correspondant à une occurrence du mot contenu dans la variable w
- 23. Développement de programmes MapReduce • le reduce remet à zéro le compteur wordCount lorsque l’on change de mot • pour chaque valeur v dans la liste inValue2 on ajoute v à wordCount • quand on change de mot, on écrit dans un fichier en sortie le couple <inKey2, wordCount>
- 24. Installation • Préparation de l’environement – On suppose que le package de java est déjà installé • Adding a dedicated Hadoop user – $ sudo addgroup hadoop • Installing SSH – $ sudo apt-get install ssh • Create and Setup SSH Certificates – $ su hduser Password: hduser@laptop:~$ ssh-keygen -t rsa -P "" Generating public/private rsa key pair. Enter file in which to save the key (/home/hduser/.ssh/id_rsa): Created directory '/home/hduser/.ssh'. Your identification has been saved in /home/hduser/.ssh/id_rsa. Your public key has been saved in /home/hduser/.ssh/id_rsa.pub. The key fingerprint is
- 25. Installation • Install Hadoop – $ wget http://mirrors.sonic.net/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0.tar.gz – tar xvzf hadoop-2.6.0.tar.gz – sudo mv * /usr/local/hadoop [sudo] password for hduser: hduser is not in the sudoers file. This incident will be reported. – sudo su hduser hduser@laptop:~/hadoop-2.6.0$ sudo mv * /usr/local/hadoop hduser@laptop:~/hadoop-2.6.0$ sudo chown -R hduser:hadoop /usr/local/hadoop • Configuration • Setup Configuration Files – /.bashrc – /usr/local/hadoop/etc/hadoop/hadoop-env.sh – /usr/local/hadoop/etc/hadoop/core-site.xml – /usr/local/hadoop/etc/hadoop/mapred-site.xml.template – /usr/local/hadoop/etc/hadoop/hdfs-site.xml
- 26. Configuration Configuration du ~/.bashrc hduser@laptop:~$ vi ~/.bashrc #HADOOP VARIABLES START export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END
- 27. Configuration • Configuration hadoop-env.sh /usr/local/hadoop/etc/hadoop/hadoop-env.sh $ vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 • Configuration core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml $ vi /usr/local/hadoop/etc/hadoop/core-site.xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property> </configuration>
- 28. Configuration Configuration du mapred-site.xml • /usr/local/hadoop/etc/hadoop/mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:54311</value> <description>The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process a single map and reduce task. </description> </property> </configuration> Configuration du hdfs-site.xml • /usr/local/hadoop/etc/hadoop/hdfs-site.xml • <configuration> <property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop_store/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop_store/hdfs/datanode</value> </property> </configuration>
- 29. Lancement de Hadoop • Format the New Hadoop Filesystem • $ hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it • Starting Hadoop cd /usr/local/hadoop/sbin /usr/local/hadoop/sbin$ ls /usr/local/hadoop/sbin$ sudo su hduser /usr/local/hadoop/sbin$ start-all.sh • Verification /usr/local/hadoop/sbin$ jps 9026 NodeManager 7348 NameNode 9766 Jps 8887 ResourceManager 7507 DataNode Stopping Hadoop /usr/local/hadoop/sbin$ ls $ stop-all.sh
- 30. Interface web d’hadoop /usr/local/hadoop/sbin$ start-all.sh