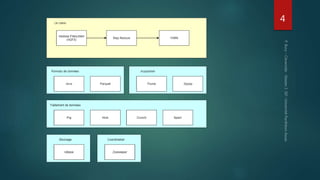
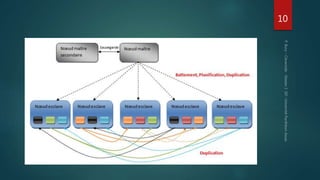
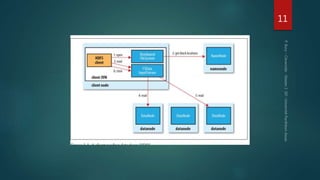
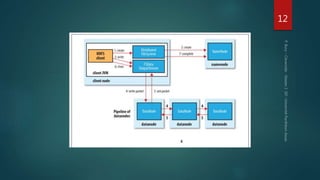
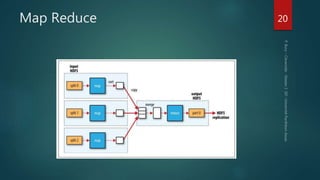
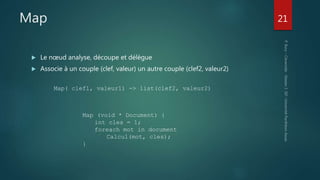
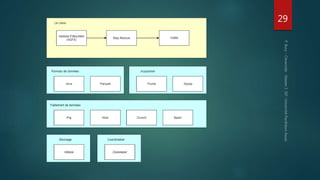
Hadoop est une plateforme de traitement de données distribuées, conçue pour gérer de grands volumes de données via des systèmes tels que HDFS et YARN. Elle se compose de divers composants comme le Namenode et les Datanodes pour le stockage, ainsi que MapReduce pour le traitement, tout en incluant des outils comme Pig et Hive pour le requêtage. Malgré ses avantages, Hadoop présente des limitations, notamment en matière de gestion des petits fichiers et de performances liées aux opération bloquantes.