Téléchargé 488 fois



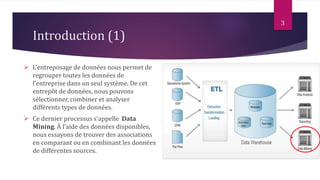






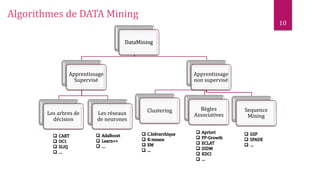





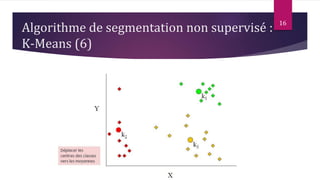







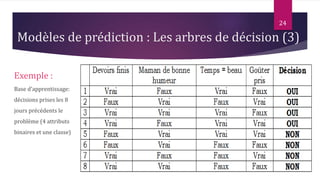

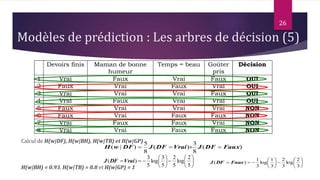
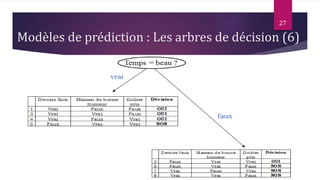
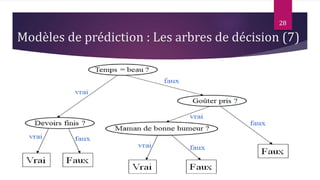


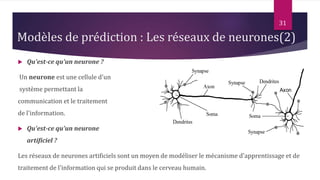
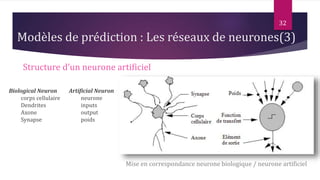
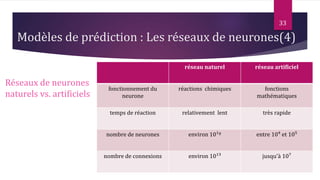
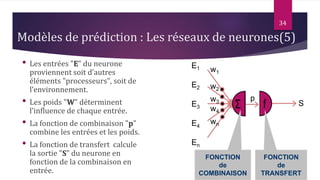
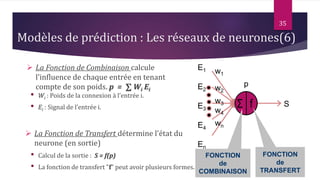
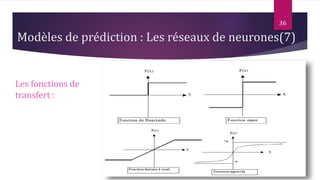






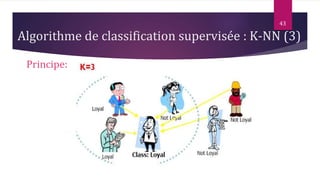
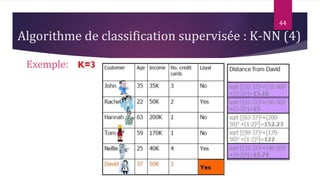




Le document présente les techniques et algorithmes de data mining, mettant en évidence les processus de classification, d'association et de segmentation. Il explore l'historique, les tâches spécifiques, et des algorithmes comme k-means et les arbres de décision, illustrant leur utilisation dans divers domaines. L'accent est mis sur l'extraction d'informations pertinentes à partir de grandes bases de données pour soutenir la prise de décision dans les organisations.






































































