




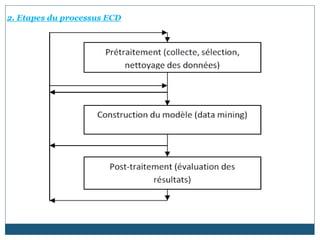










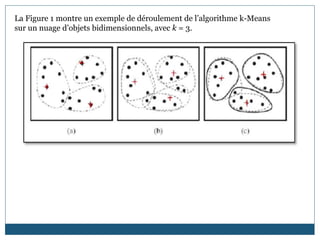




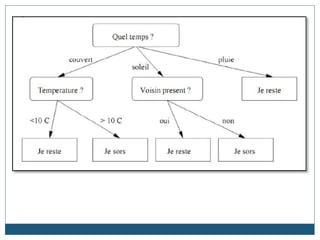




Le document traite des techniques de data mining et de leur rôle dans le processus d'extraction de connaissances à partir de données. Il présente les étapes du processus d'ECD, définit les tâches et techniques associées, et décrit plusieurs algorithmes populaires tels que k-means et k-medoids. Les domaines d'application sont variés, allant des entreprises commerciales au secteur médical, tout en soulignant les défis liés à la qualité des données et au choix des algorithmes.















































