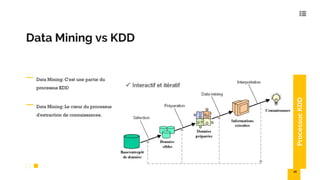
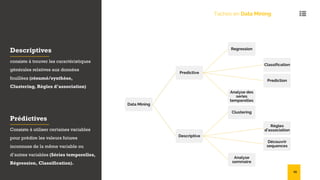
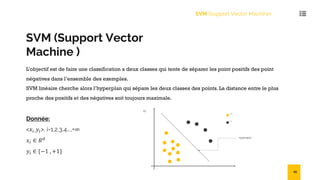
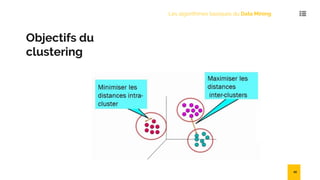
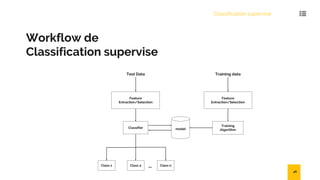
Le document présente une introduction au data mining, ses techniques, et ses applications dans divers secteurs tels que l'éducation, l'assurance, et le commerce. Il détaille également les étapes et algorithmes de data mining, y compris la classification, le clustering, et les modèles prédictifs. Les challenges et avantages des méthodes comme SVM et k-NN sont également abordés.