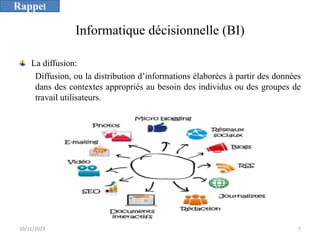
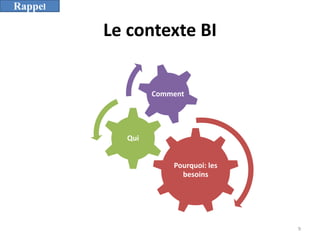
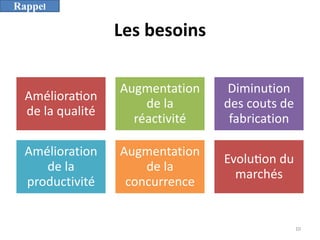
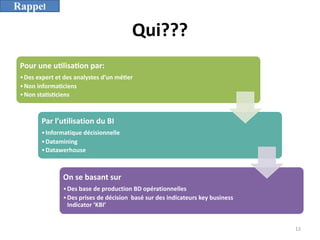
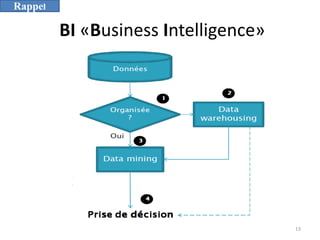
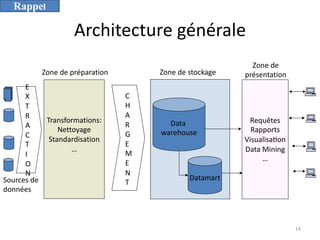
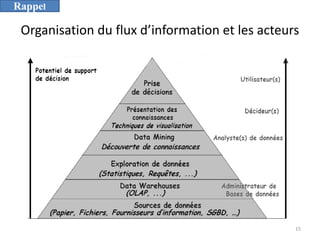
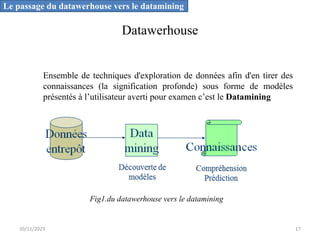
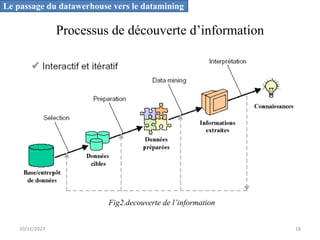
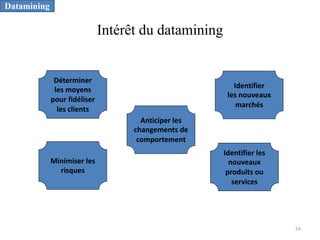
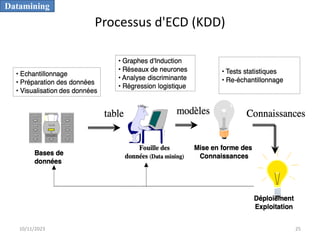
L'informatique décisionnelle (BI) consiste en un ensemble d'outils et de méthodes pour collecter, modéliser et restituer des données d'entreprise afin d'assister la prise de décision. Le document aborde également le concept de data mining, qui permet d'extraire des connaissances à partir de grandes quantités de données pour orienter les décisions stratégiques. Enfin, il souligne l'importance d'une approche méthodique et réfléchie lors de l'application des techniques de data mining.