




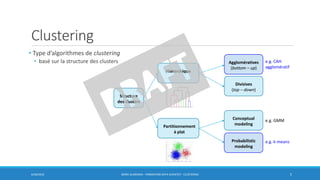


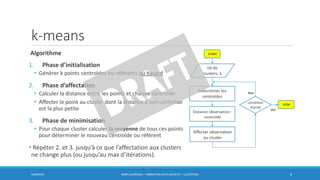

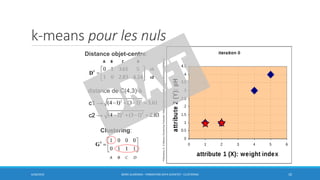


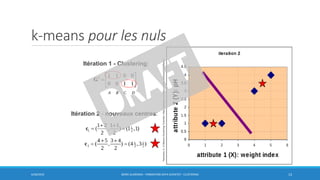
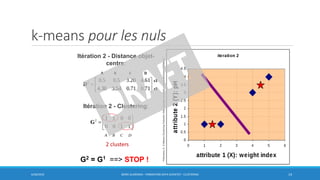



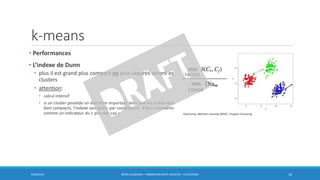











Ce document traite des méthodes de clustering, principalement le k-means et la classification ascendante hiérarchique (CAH), en détaillant leurs algorithmes, applications et mesures de performance. Il souligne la différence entre l'apprentissage supervisé et non supervisé, ainsi que l'importance de la distance et de la similarité dans le regroupement des données. Enfin, des pratiques pour déterminer le nombre optimal de clusters et des considérations sur leurs avantages et inconvénients sont également abordées.



























![Comprendre l’intelligence artificielle [webinaire]](https://cdn.slidesharecdn.com/ss_thumbnails/technologiawebinaireintelligenceartificielleclaudemarson01042019-190403213713-thumbnail.jpg?width=640&height=640&fit=bounds)







































