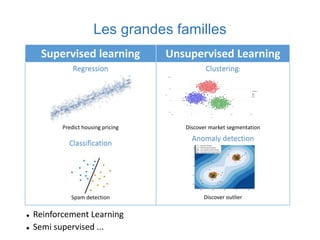
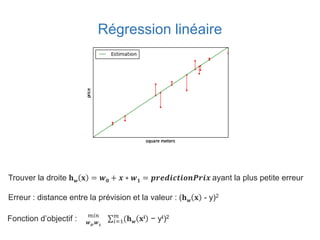
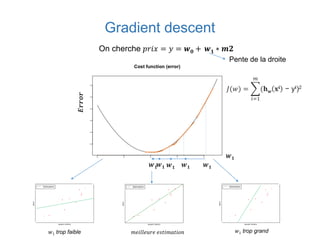
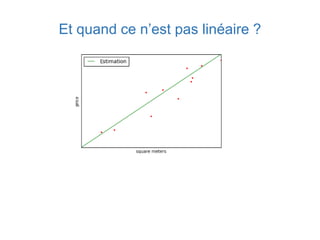
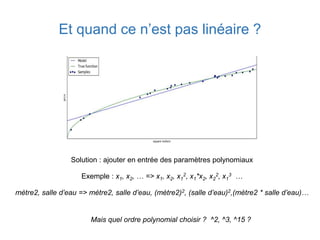
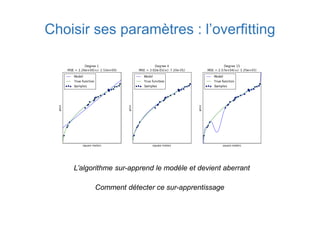
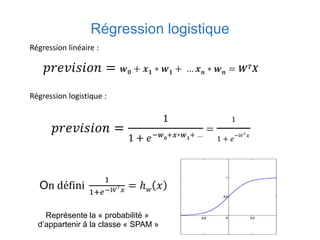
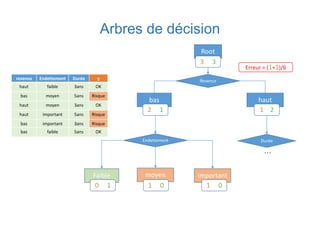
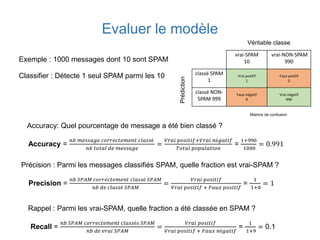
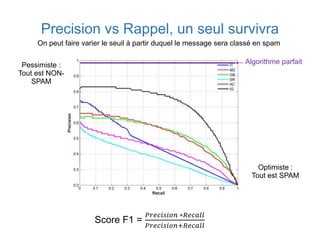
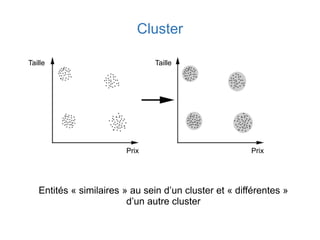
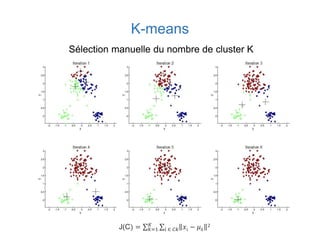
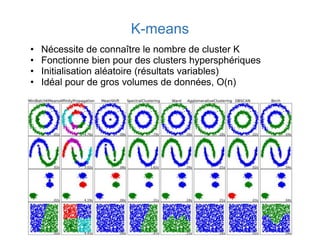
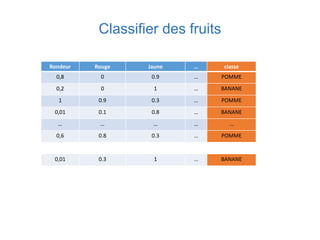
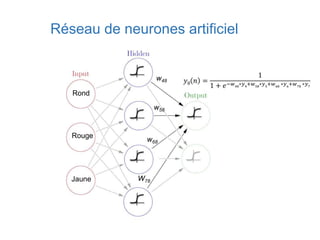
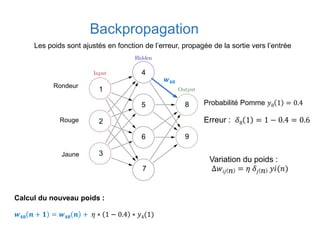
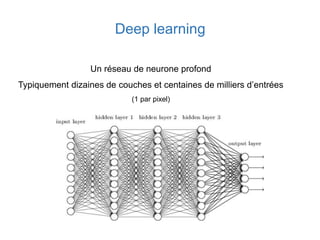
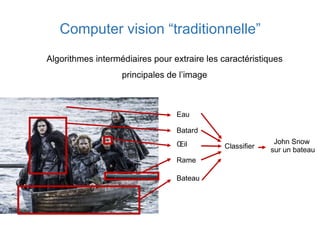
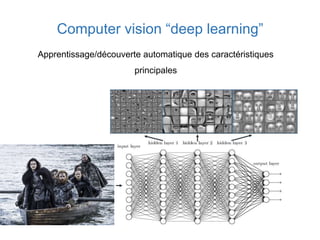
Ce document présente une introduction au machine learning, abordant des concepts clés tels que la régression linéaire, la classification, et les réseaux de neurones. Il explique les différentes techniques de machine learning, comme l'apprentissage supervisé et non supervisé, ainsi que des exemples d'applications pratiques. Enfin, il souligne l'importance de l'évaluation des modèles et discute des outils et frameworks populaires dans ce domaine.








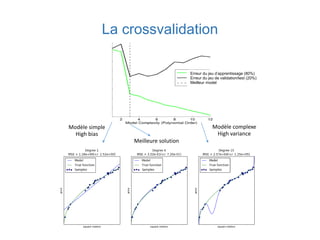

![Un exemple avec Scikit-Learn
#Get the data formatted
data = get_formatted_data()
#extract features and prices
features = data [[‘m2’, ‘salle-de-bain’, ’etage’]]
price = data[‘price’ ]
#Split with train and test dataset
features_train, features_test, price_train, price_test =
sklearn.cross_validation.train_test_split( features, price)
#Build and train the model with the train dataset
regression = linear_model.LinearRegression()
regression.fit(features_train, price_train)
#Get the residual sum of squares from the test dataset
RSS = np.sum((regression.predict(features_test) - price_test) ** 2))
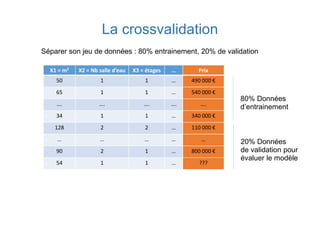
X1 = m2 X2 = Nb salle
d’eau
X3 = étages … Prix
50 1 1 … 490 000 €
65 1 1 … 540 000 €
…. …. …. …. ….
34 1 1 … 340 000 €
128 2 2 … 110 000 €
… … … … …
90 2 1 … 800 000 €
54 1 1 … ???](https://image.slidesharecdn.com/machine-learning-180428205348/85/Introduction-to-Machine-learning-19-320.jpg)







































![Comprendre l’intelligence artificielle [webinaire]](https://cdn.slidesharecdn.com/ss_thumbnails/technologiawebinaireintelligenceartificielleclaudemarson01042019-190403213713-thumbnail.jpg?width=640&height=640&fit=bounds)



























