Téléchargé 25 fois















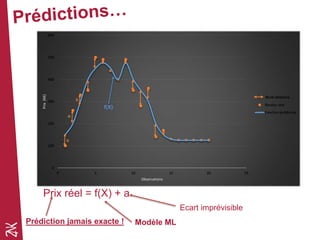
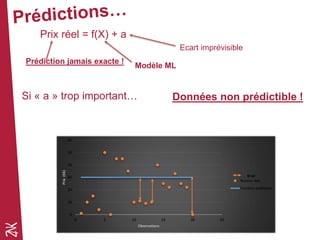
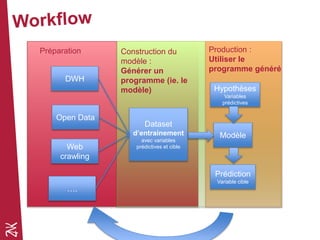



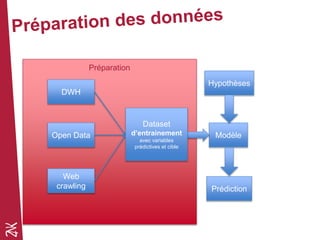

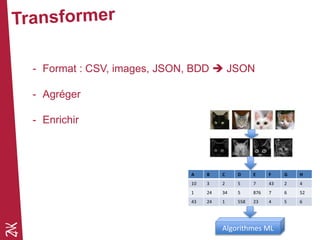
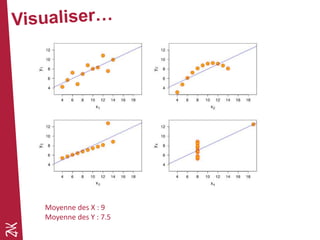


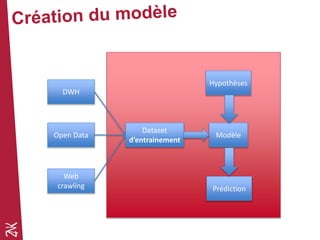


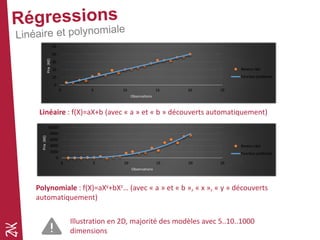


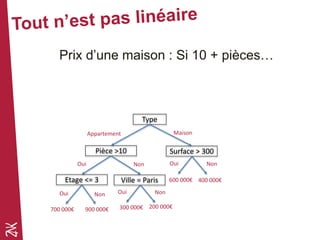






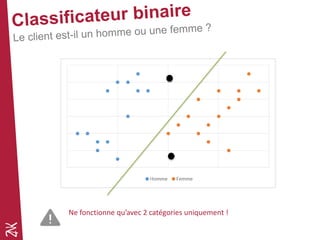
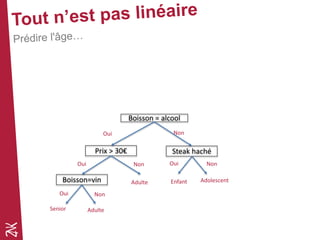
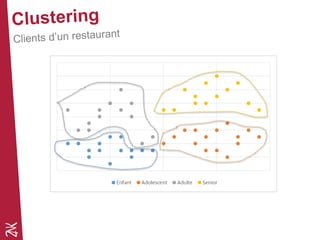
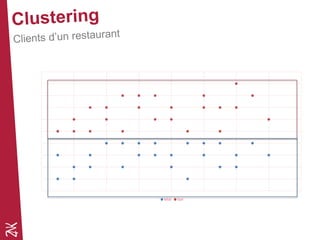

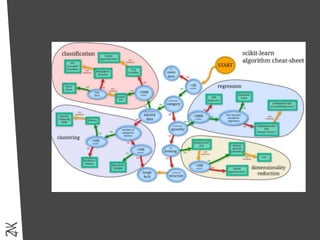








Le document présente une introduction au machine learning, en se concentrant sur ses bases, ses algorithmes, et son application dans divers domaines comme la prédiction, la recommandation et la classification. Il souligne l'importance de la préparation des données pour l'efficacité des algorithmes et propose des outils et méthodes pour le prototypage et l'industrialisation des modèles. Enfin, il mentionne plusieurs algorithmes, y compris ceux de régression et de classification, ainsi que des frameworks de Big Data utilisés dans le domaine.



















































