Télécharger en tant que PDF, PPTX







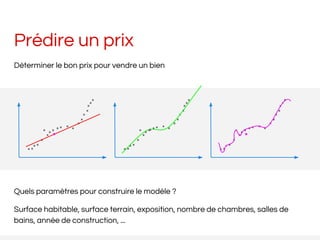













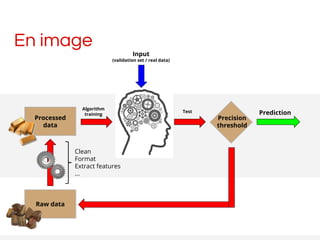











Le document présente une introduction au machine learning, en expliquant ses principes, ses paradigmes et les différents algorithmes appliqués. Il met également en avant l'outil Apache Spark comme une solution performante pour le traitement des données massives, avec des capacités d'apprentissage automatique variées. Enfin, il souligne l'importance de bien préparer les données et de sélectionner les algorithmes adéquats pour assurer des prédictions fiables.