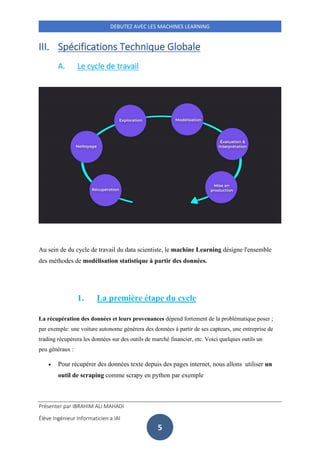
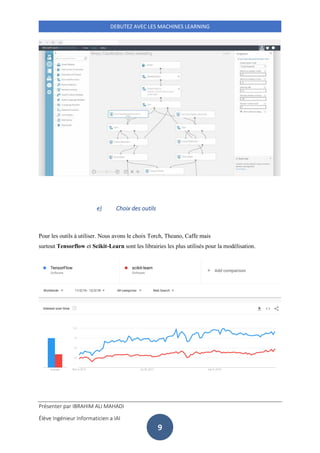
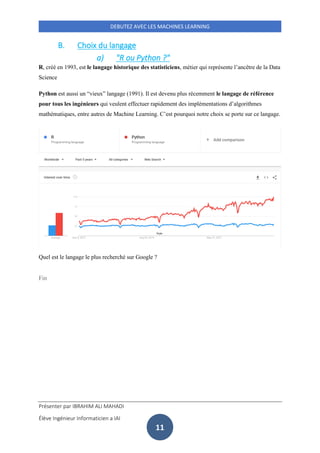
Ce document présente une introduction au machine learning pour débutants, en décrivant des concepts clés tels que les données structurées et non structurées, la data science et le clustering. Il examine également le cycle de travail des data scientists, les étapes impliquées dans la modélisation statistique et cite des algorithmes courants comme la régression linéaire et k-nearest neighbors. Enfin, il aborde les choix technologiques, y compris les langages de programmation adaptés à la data science, en privilégiant Python.