Télécharger en tant que PDF, PPTX






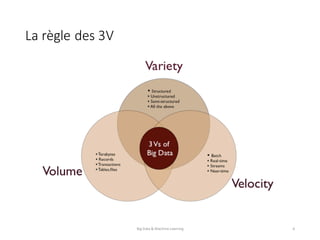




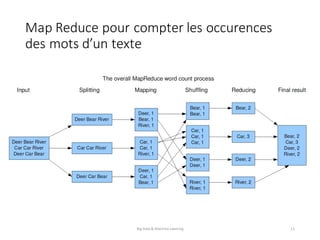


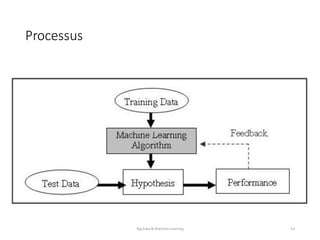



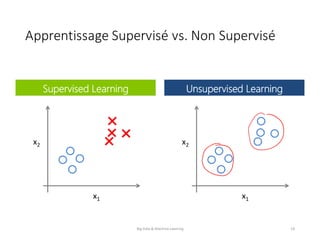




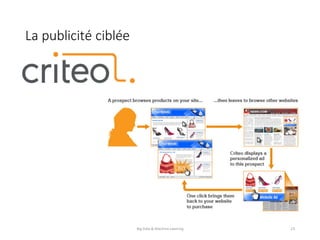




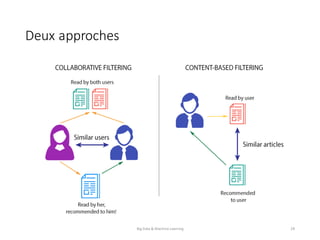




Le document présente une introduction au big data et au machine learning, en abordant leurs définitions, leurs applications et les différentes approches d'apprentissage. Il discute également des infrastructures nécessaires pour traiter d'énormes volumes de données et des méthodes comme le filtrage collaboratif pour les recommandations. En conclusion, le domaine est en pleine expansion avec de nombreuses applications à impact direct sur les utilisateurs.


































![[Harvard CS264] 09 - Machine Learning on Big Data: Lessons Learned from Googl...](https://cdn.slidesharecdn.com/ss_thumbnails/machinelearningbigdata-maxlin-cs264opt-110331195757-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































