Télécharger en tant que PDF, PPTX





![© Karim Baïna 2016 6
Réponses aux 4 V
● VELOCITE
– Collecte des données réactive à la fréquence de leur arrivée
– Réponse on time (ponctuelle) pas nécessairement « temps réel »
● VOLUME
– stockage réparti sur un réseau de machines (cloud)
– calculs parallèles sur les données réparties (grid)
● VARIETE
– Prise en charge des données brutes [non|semi| ]-structurées et multi-
format (texte|..|matrice|graphe|image|audio|vidéo)
● VERACITE
– Traçabilité de la provenance, assurance de la vérifiabilité en dédoublant les
sources de données, adoption d'un plan de qualité des données](https://image.slidesharecdn.com/baina-bigdata-introduction-2016-160524225437/85/Baina-bigdata-introduction-2016-6-320.jpg)













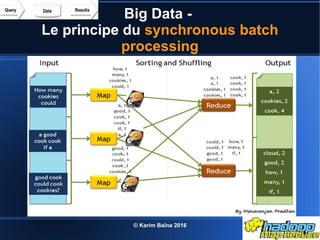

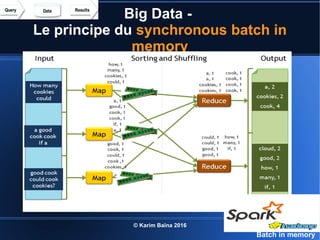
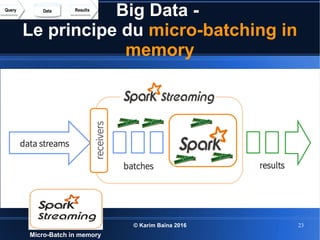

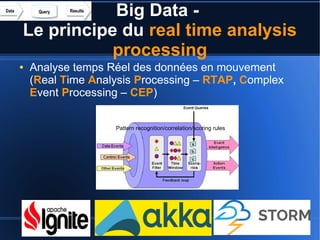

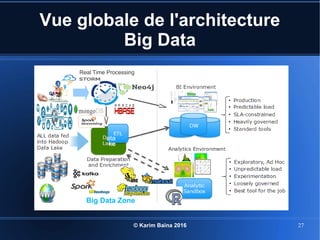

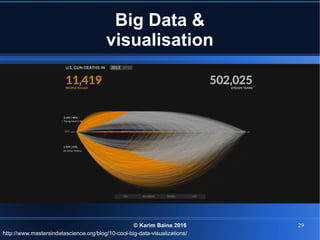
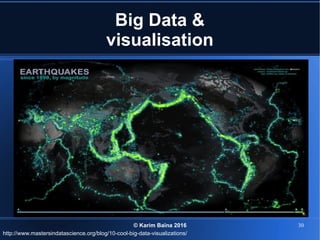
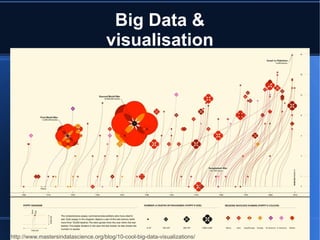
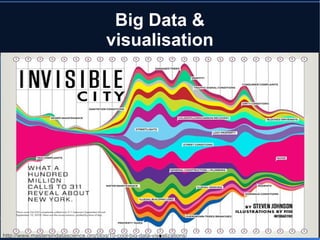
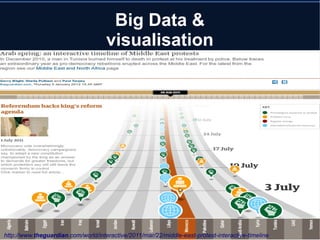





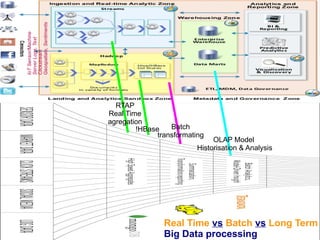
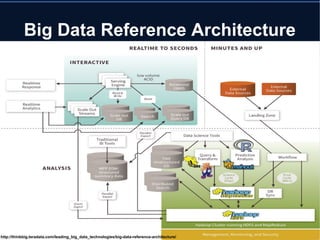
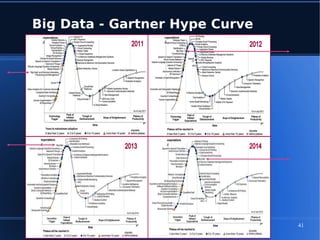

Le document aborde le concept de big data, soulignant les défis et opportunités associés à son volume, sa vélocité, sa variété et sa véracité. Il présente également des cas d'utilisation pratiques, tels que la sécurité urbaine et l'analyse des sentiments sur les réseaux sociaux, ainsi que les stratégies de traitement des données. Enfin, le document discute des compétences nécessaires pour devenir spécialiste en big data et souligne les bénéfices potentiels pour le Maroc.























































































