Télécharger en tant que PDF, PPTX





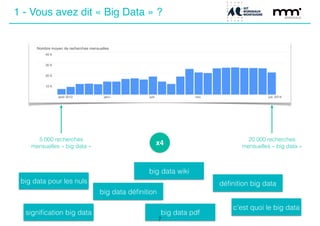









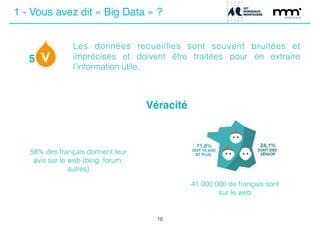



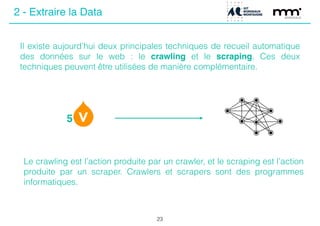


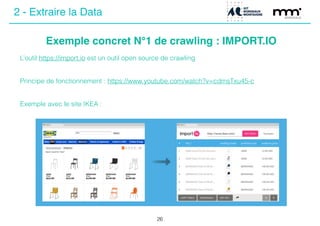










Le document présente une journée de formation sur le big data, expliquant les concepts, les enjeux et les différentes méthodes de traitement des données. Il aborde les types de données, leur volume croissant, ainsi que les techniques d'extraction comme le crawling et le scraping. La conclusion souligne l'importance de l'éthique dans la collecte et le traitement des données personnelles.



































































