Télécharger en tant que PDF, PPTX










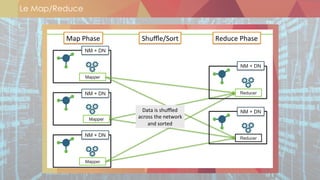

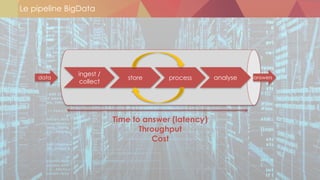
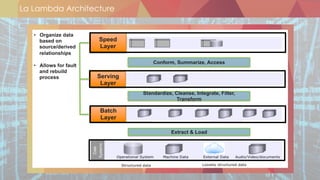
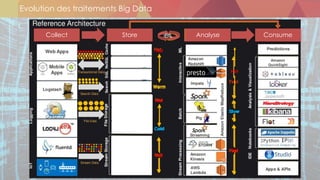

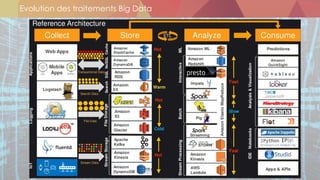
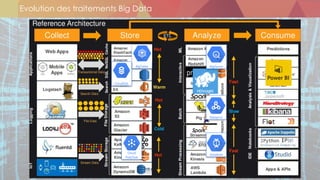
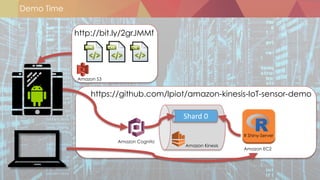

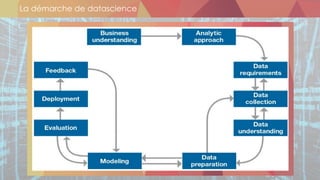





![Sources
• [6, 10] : Hortonworks : Operations Management with HDP
• [8, 11, 12] : http://www.slideshare.net/1Strategy/2016-utah-cloud-summit-big-
data-architectural-patterns-and-best-practices-on-aws](https://image.slidesharecdn.com/20161215morningtechbigdata-170319170234/85/Oxalide-MorningTech-1-BigData-31-320.jpg)





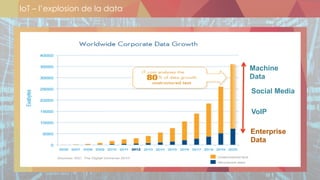
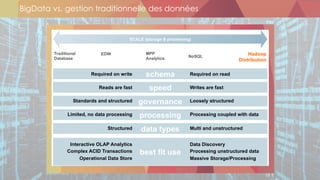
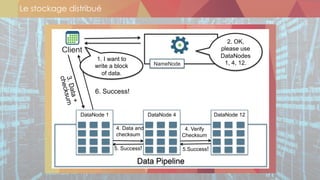
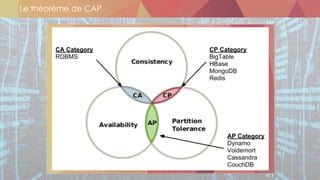
Le document présente les différentes thématiques abordées lors des événements organisés par Oxalide, axés sur les technologies Big Data et les enjeux associés. Il décrit les types de sessions, y compris des rencontres informelles et des ateliers techniques pour les clients, ainsi que l'évolution des stratégies de gestion des données face à l'explosion des volumes et variétés de données. Enfin, il aborde des concepts clés du Machine Learning et des plateformes de traitement de données en temps réel, soulignant leur importance dans le contexte des applications Big Data.













![[French] Matinale du Big Data Talend](https://cdn.slidesharecdn.com/ss_thumbnails/matinaledubigdatatalend-141008041011-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Capitole du Libre] #serverless - mettez-le en oeuvre dans votre entreprise...](https://cdn.slidesharecdn.com/ss_thumbnails/capitoledulibre2018serverless-181120135943-thumbnail.jpg?width=640&height=640&fit=bounds)













