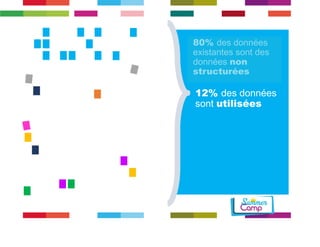
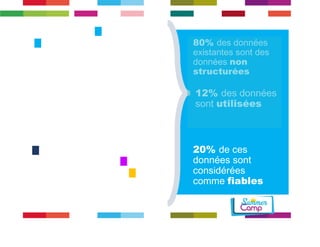
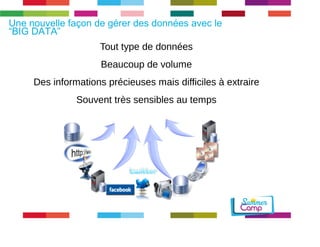
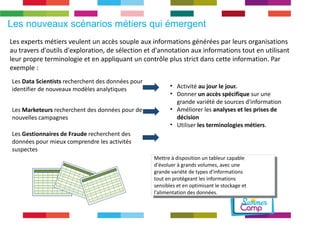
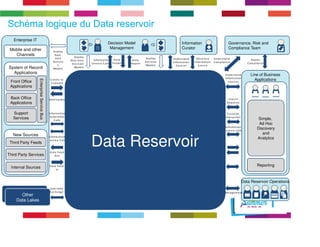
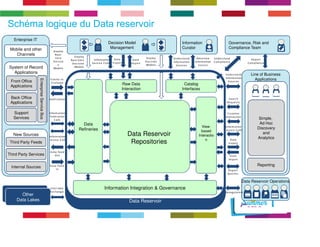
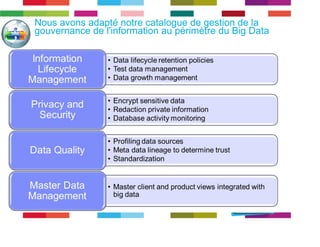
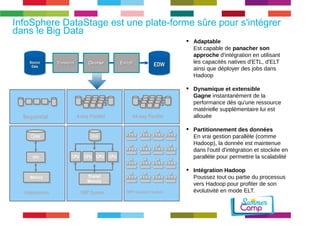
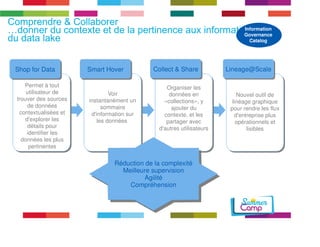
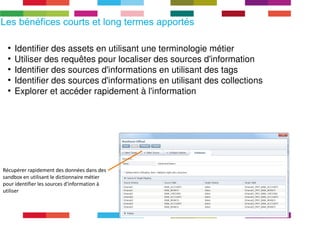
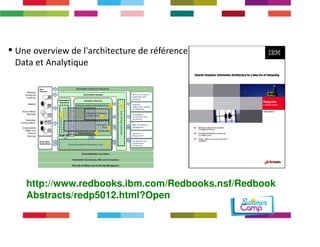
Le document discute de l'importance de la gouvernance des données pour réussir les initiatives d'analytique, en mettant l'accent sur les défis liés à la gestion et à l'utilisation des données non structurées. Il présente des concepts tels que les data lakes et data reservoirs, qui permettent une analyse flexible et en temps réel, tout en soulignant la nécessité d'établir des règles de gouvernance pour assurer l'intégrité et la confidentialité des données. Enfin, il souligne que la majorité des efforts dans les projets de big data sont consacrés à l'intégration des données plutôt qu'à leur analyse.








































![[French] Matinale du Big Data Talend](https://cdn.slidesharecdn.com/ss_thumbnails/matinaledubigdatatalend-141008041011-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[Fr] Information builders - MDM et Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/information-builders-mdm-bigdata-131016140315-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























