Télécharger en tant que PDF, PPTX








![Hands-on #1
API REST
verbe HTTP Type de ressources Exemple
GET
Documents
/twitter/tweet/AVNXnwSH24f3KF5HzrfR?pretty
PUT / POST
/twitter/tweet/AVNXnwSH24f3KF5HzrfR/_create
/twitter/tweet/AVNXnwSH24f3KF5HzrfR?version=1
/twitter/tweet/AVNXnwSH24f3KF5HzrfR?version=5&version_type=external
DELETE /twitter/tweet/AVNXnwSH24f3KF5HzrfR
POST Recherche
/twitter/tweet/_search
/twitter/_search
/_search
GET
Metadonnées
/twitter/_status
/_cluster/status | state | health | settings
/nodes | index/_stats
/_stats
/_search
/_cat
POST /_shutdown (supprimé en v2.x)
http://host:port/[index]/[type]/[_action/id] : remember where / what / which](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-14-320.jpg)
![Hands-on #1
Recherche et document JSON
Query DSL (JSON) Document JSON
{ "query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"and": [
{
"range" : {
"b" : {
"from" : 4,
"to" : "8"
}
},
},
{
"term": {
"a": "john"
}
}
]}}
}
}
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-15-320.jpg)
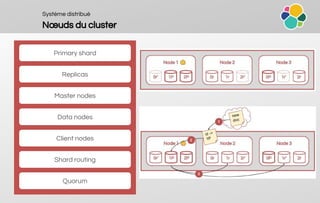
![Hands-on #1
Configuration du cluster
Script de démarrage Fichier de configuration
$ cat …/config/elasticsearch.yml
# Use a descriptive name for your cluster:
cluster.name: elastic-wkshop
# Use a descriptive name for the node:
node.name: elastic-wkshop-1
# Path to directory where to store the data:
path.data: /es/data
# Path to log files:
path.logs: /es/logs
# Lock the memory on startup:
bootstrap.mlockall: true
# Set the bind address to a specific IP (IPv4 or IPv6):
network.host: 172.31.23.121
# Set a custom port for HTTP:
http.port: 9200
# Pass an initial list of hosts to perform discovery when new node is started:
discovery.zen.ping.unicast.hosts: ["elastic-wkshop-
1", "elastic-wkshop-2", "elastic-wkshop-3"]
# Prevent the "split brain" by configuring the majority of nodes (total number
of nodes / 2 + 1):
discovery.zen.minimum_master_nodes: 2
$ cat …/bin/elasticsearch
ES_JAVA_OPTS="-Xms8192m -
Xmx8192m"
ES_HEAP_SIZE="8g"](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-16-320.jpg)


![Comment ça marche ?
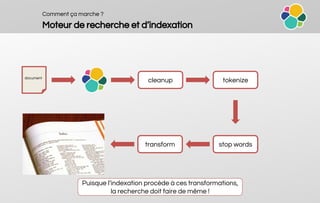
Mapping
Principes
PUT /[index]/_mapping
Mapping par défaut : {“_default_”: {}}
Dans un même index, tous les champs
du même nom DOIVENT avoir le même
mapping même si ils appartiennent à
des types différents
Exemple
{
"twitter": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd"
},
"text": {
"type": "string",
"index": "analyzed"
},
"user_id": {
"type": "long"
}
}
}
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-24-320.jpg)
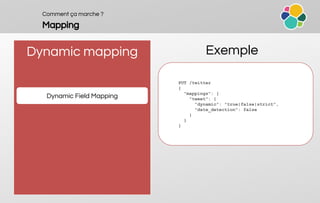
![Comment ça marche ?
Mapping
Dynamic mapping
Default Mapping
Exemple
{
"twitter": {
"mappings": {
"_default_": {
"dynamic_templates": [{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "string",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed",
"ignore_above": 256
}
}
}
}
}]
}
}
}
}
Dynamic Templates](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-26-320.jpg)
![Comment ça marche ?
Mapping
Dynamic Mapping
Index Template
Exemple
PUT /_template/template_twitter
{
"template" : "twitter-*",
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"tweet" : {
[...]
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-27-320.jpg)
![Comment ça marche ?
Mapping
Mise à jour
On peut ajouter un nouveau field
On ne peut pas changer un field existant
Solution
On ne peut pas supprimer un mapping
(2.x)
Créer un nouvel index et tout ré-indexer :
Scroll Query + Bulk API
Alias d’index :
● index_v1
● index_v2
● index_v3
index => index_v3
PUT /[index]/_alias/[alias]](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-28-320.jpg)
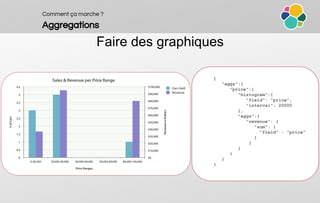
![Comment ça marche ?
Aggregations
Comment s’en servir
POST /twitter/tweet/_search
{
"query": [...],
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-29-320.jpg)
![Comment ça marche ?
Aggregations
Buckets Exemple
Buckets ≈ GROUP BY
Buckets => doc_count
Buckets inside Buckets
{
[...],
"aggregations": {
"hashtags": {
"buckets": [
{
"key": "IWD2016",
"doc_count": 4
},
{
"key": "heforshe",
"doc_count": 2
},
{
"key": "women",
"doc_count": 2
}
]
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-30-320.jpg)
![Comment ça marche ?
Aggregations
Metrics Exemple
Metrics ≈ SUM/AVG/MIN/MAX
Metrics inside Buckets
Metrics inside Metrics
{
[...],
"aggregations": {
"user_follower_stats": {
"count": 4871628,
"min": 0,
"max": 72529214,
"avg": 5242.441252493007,
"sum": 25539223594
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-31-320.jpg)
![Comment ça marche ?
Aggregations
Mutiple Exemple
{
[...],
"aggregations": {
"grades_stats": {
"count": 6,
"min": 60,
"max": 98,
"avg": 78.5,
"sum": 471
},
"user_follower_stats": {
"count": 456,
"min": 0,
"max": 9868,
"avg": 78.5,
"sum": 785786735
}
}
}
{
"aggregations": {
"grades_stats": {
"stats": {
"field": "grades"
},
},
"user_follower_stats": {
"stats": {
"field": "followers_count"
},
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-32-320.jpg)
![Comment ça marche ?
Aggregations
Nestable Exemple
"aggregations": {
"hashtag": {
"buckets": [
{
"key": "internationalwomensday",
"doc_count": 3334427,
"retweeted": {
"buckets": [
{
"key": 0,
"doc_count": 1334426
},
{
"key": 1,
"doc_count": 2000001
}
]
}
}
]
}
}
{
"aggregations": {
"hashtag": {
"terms": {
"field": "hastags"
},
"aggregations": {
"retweeted": {
"terms": {
"field": "retweeted"
}
}
}
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-33-320.jpg)
![Comment ça marche ?
Aggregations
Sortable Exemple
"aggregations": {
"hashtag": {
"buckets": [
{
"key": "a",
"doc_count": 64987,
},
{
"key": "b",
"doc_count": 789,
},
{
"key": "b",
"doc_count": 236,
}
]
}
}
{
"aggregations": {
"hashtag": {
"terms": {
"field": "hastag",
"order": {
"_term": "asc"
}
}
}
}
}](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-34-320.jpg)



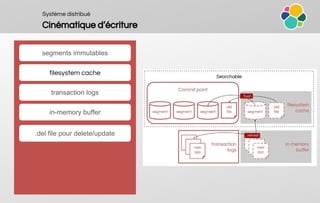
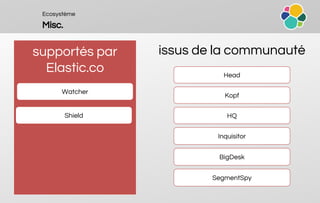
![Ecosystème
Logstash & Beats
ETL en Java
support de plugins
input {
twitter {
consumer_key => "…"
consumer_secret => "…"
oauth_token => "…"
oauth_token_secret => "…"
full_tweet => true
keywords => [ "journeedesdroitsdesfemmes",
"journeedelafemme" ]
}
}
filter {
}
output {
stdout { codec => dots }
elasticsearch {
hosts => [ "172.31.23.121" ]
index => "twitter"
document_type => "tweet"
template_name => "tpl_twitter"
}
}
configuration en JSON
Beats = framework Go](https://image.slidesharecdn.com/workshop-3elasticsearchlpiot20160310-160314161931/85/Oxalide-Workshop-3-Elasticearch-an-overview-40-320.jpg)




Le document présente un atelier sur Elasticsearch, mettant en avant ses objectifs de formation et d'échange pour différents publics. Il aborde les fonctionnalités techniques, les usages principaux, la structure des données et les outils associés comme Kibana et Logstash. Des sessions pratiques sont également incluses pour aider à la compréhension et à l'application des concepts discutés.
















![[Breizhcamp 2015] MongoDB et Elastic, meilleurs ennemis ?](https://cdn.slidesharecdn.com/ss_thumbnails/mongodbetelasticmeilleursennemis-150612210744-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Sildes] plateforme centralisée d’analyse des logs des frontaux http en temps...](https://cdn.slidesharecdn.com/ss_thumbnails/sildesplateformecentralisedanalysedeslogsdesfrontauxhttpentempsreldansunmilieuvirtualis-160429150553-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Capitole du Libre] #serverless - mettez-le en oeuvre dans votre entreprise...](https://cdn.slidesharecdn.com/ss_thumbnails/capitoledulibre2018serverless-181120135943-thumbnail.jpg?width=640&height=640&fit=bounds)








