Télécharger en tant que PDF, PPTX








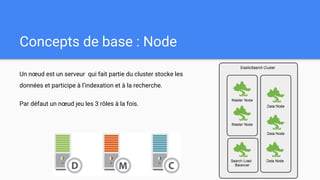
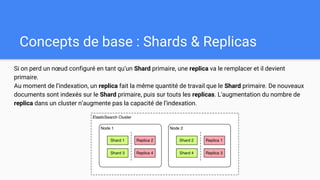

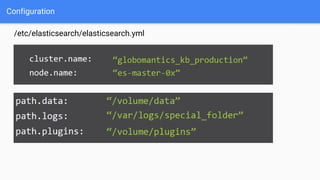
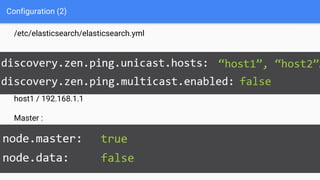
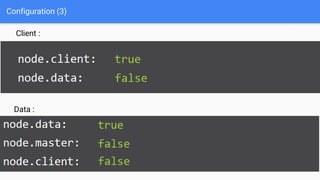
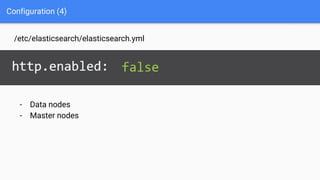

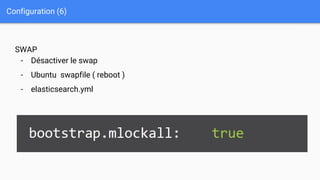
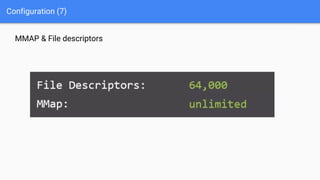


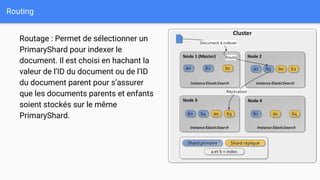




Ce document présente une introduction à Elasticsearch, un moteur de recherche NoSQL basé sur Lucene, en abordant son architecture, sa configuration, ainsi que ses concepts essentiels tels que les clusters, les nœuds, les shards et les réplicas. Il détaille également le processus d'installation et de configuration du logiciel, ainsi que ses fonctionnalités comme le routage, les alias et le snapshotting. Enfin, des ressources supplémentaires sont fournies pour approfondir l'apprentissage d'Elasticsearch.






































![[Breizhcamp 2015] MongoDB et Elastic, meilleurs ennemis ?](https://cdn.slidesharecdn.com/ss_thumbnails/mongodbetelasticmeilleursennemis-150612210744-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)








