Télécharger en tant que PDF, PPTX






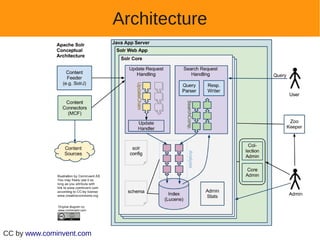










Le document présente Apache Solr, un moteur de recherche basé sur Apache Lucene, utilisé par Kelkoo pour améliorer ses fonctionnalités de recherche après la vente à Yahoo. Il couvre les caractéristiques techniques, la performance et les fonctionnalités de Solr, ainsi que la scalabilité avec SolrCloud. En conclusion, Solr est considéré comme un outil performant et économique pour des solutions de recherche, avec une large communauté de développeurs.



























































