


































































![Thomas Francart,
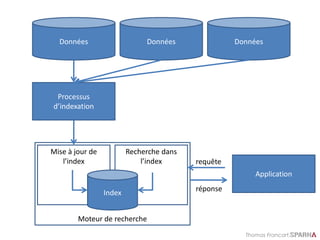
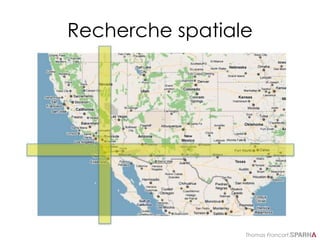
Syntaxe de recherche Lucene :
fuzzy, range, boost
• Fuzzy queries
– auteur:ewing vs. auteur:ewing~ vs.
auteur:ewing~0.8
• Range queries
– education AND annee:[1999 TO 2001]
– education AND annee:[2001 TO *]
• Score boosting
– Child primary^10](https://image.slidesharecdn.com/solr-formation-sparna-v0-150826152425-lva1-app6891/85/Solr-formation-Sparna-77-320.jpg)









![Thomas Francart,
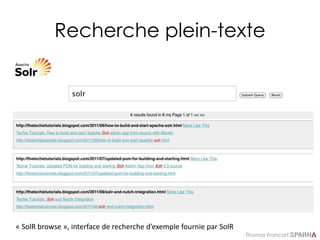
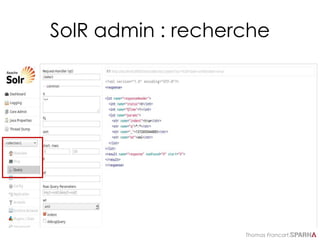
Spellcheck : résultats
<response>…
<lst name="spellcheck">
<lst name="suggestions">
<lst name="delll">
<int name="numFound">1</int>
<int name="startOffset">18</int><int name="endOffset">23</int>
<int name="origFreq">0</int>
<arr name="suggestion“><lst>
<str name="word">dell</str>
<int name="freq">2</int>
</lst></arr>
</lst>
<lst name="ultrashar">
<int name="numFound">1</int>
<int name="startOffset">24</int><int name="endOffset">33</int>
<int name="origFreq">0</int>
<arr name="suggestion“><lst>
<str name="word">ultrasharp</str>
<int name="freq">2</int>
</lst></arr>
</lst>
<bool name="correctlySpelled">false</bool>
<str name="collation">price:[80 TO 100] dell ultrasharp</str>
</lst>
</lst>
</response>](https://image.slidesharecdn.com/solr-formation-sparna-v0-150826152425-lva1-app6891/85/Solr-formation-Sparna-87-320.jpg)















![Thomas Francart,
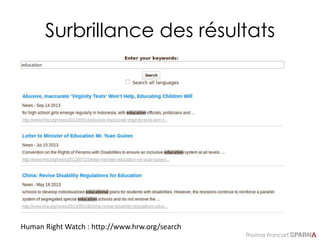
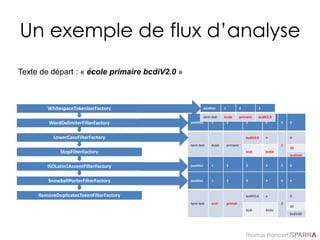
Suggestions basées sur l’index :
solution 1 : facet.prefix
…/solr/core01/select/?q=michaelfacet=on&rows=0&facet.limit=5&facet.mincou
nt=1&facet.field=text&facet.sort=count&facet.prefix=ja&qt=myHandler&wt=jso
n&indent=on&
{ "responseHeader" : {
"status":0,
"QTime":5},
"response":{"numFound":2498,"start":0,"docs":[]},
"facet_counts":{
"facet_queries":{},
"facet_fields": {
"text":[
"jackson",18,
"james",16,
"jason",4,
"jay",4,
"jane",3 ]
}
}
}](https://image.slidesharecdn.com/solr-formation-sparna-v0-150826152425-lva1-app6891/85/Solr-formation-Sparna-103-320.jpg)








Le document présente Solr, un moteur de recherche open-source basé sur Lucene, conçu pour l'indexation et la recherche de données non-structurées. Il détaille son architecture, la manière dont les index et les analyses de textes fonctionnent, ainsi que les configurations nécessaires pour son utilisation. En outre, il évoque des fonctionnalités avancées telles que la gestion des synonymes et des filtres d'analyse, soulignant l'importance de la structure des données indexées pour optimiser la recherche.




































































