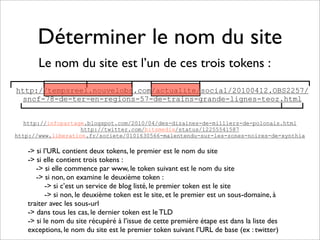
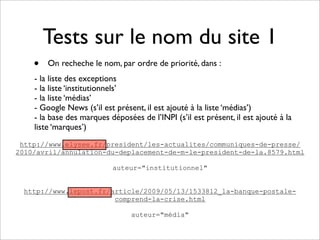
Le projet Ipinion vise à extraire des informations d'URLs sans crawler les pages, en classifiant celles-ci selon leur auteur (institutionnel, corporate, particulier, journaliste) et d'autres critères. L'analyse s'effectue à travers l'analyse de l'URL de base, de son chemin, et divers traitements postérieurs, permettant d'identifier des informations telles que le type de site, le titre de la page, et d'autres tags pertinents. À l'issue du processus, le projet génère des statistiques sur le nom du site et la typologie des auteurs pour 60 à 70 % des cas, avec plusieurs tags par URL.