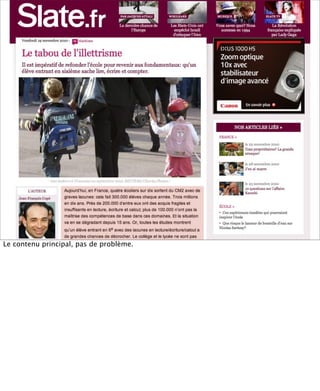
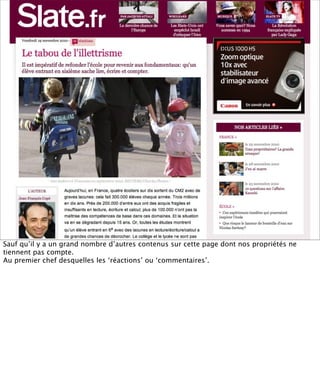
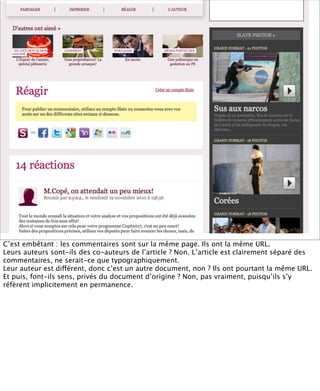
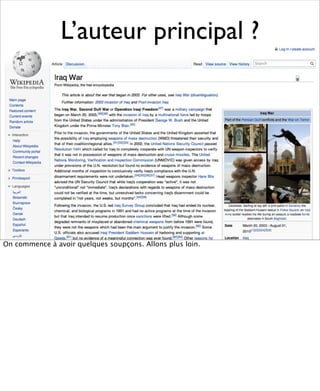
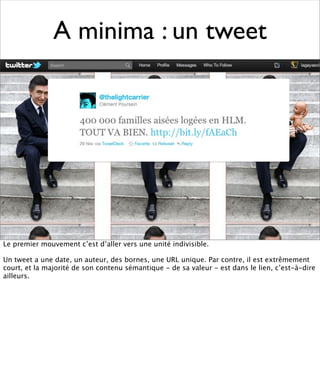
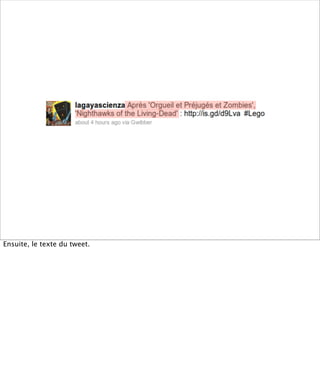
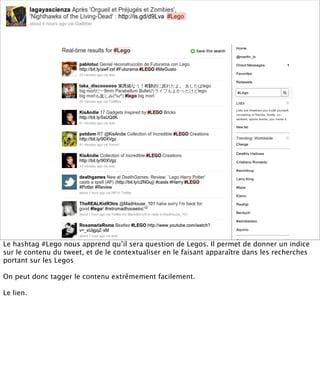
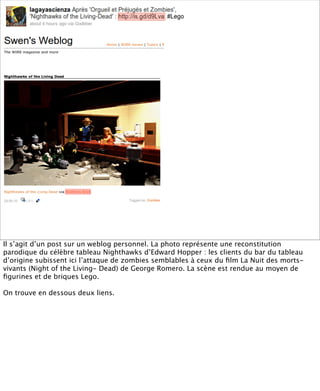
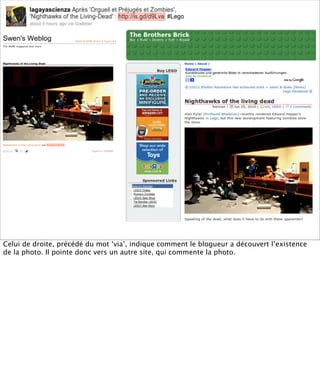
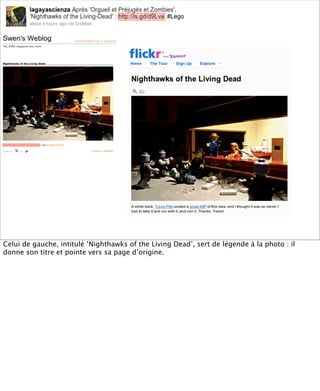
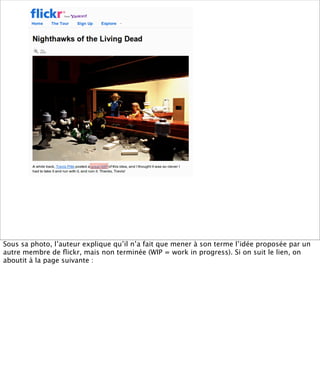
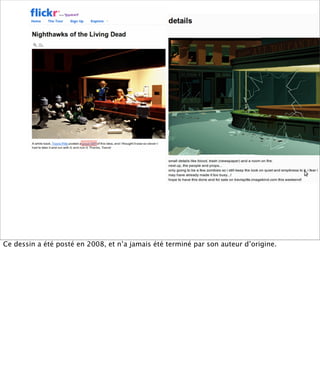
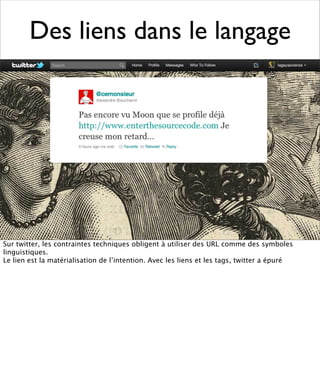
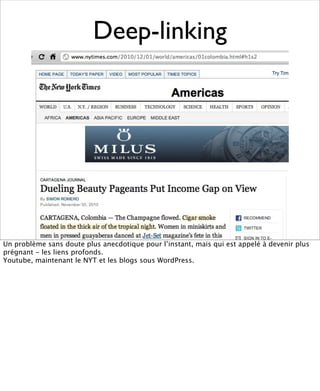
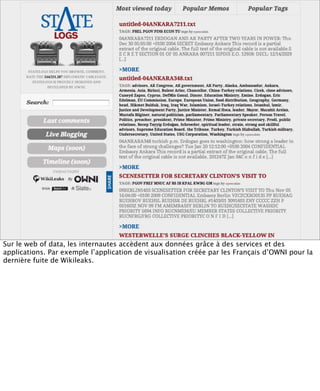
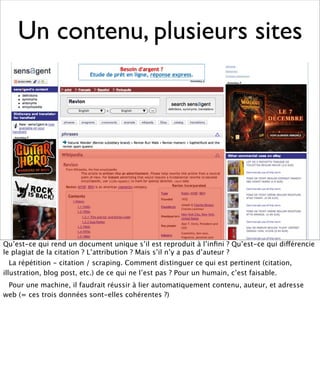
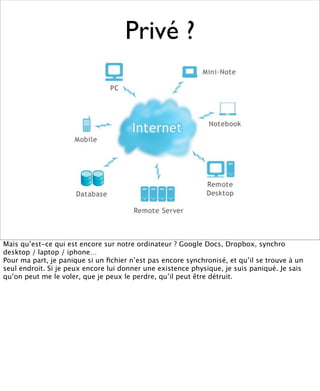
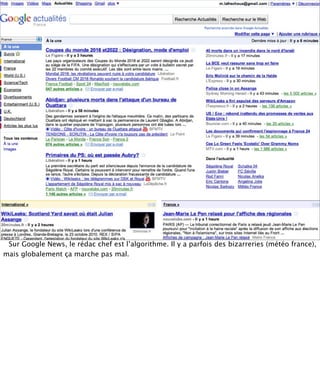
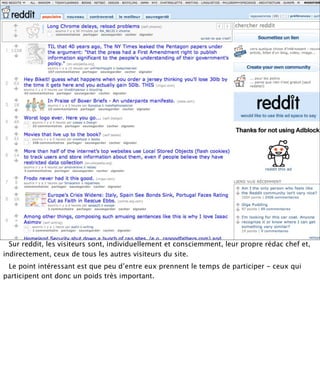
La présentation aborde les défis conceptuels et pratiques liés aux documents web, notamment l'absence de modélisation adéquate pour capturer tous les aspects d'une page. Elle souligne la complexité de définir ce qu’est un document à l'ère du web, où les notions de contenu, d'auteur et de persistance sont mises à mal. Enfin, elle discute des enjeux d'archivage et des méthodes actuelles, en concluant que le web reste difficile à enregistrer dans son intégralité.