Téléchargé 42 fois










![1919
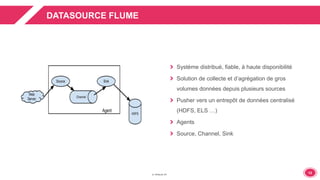
DEMO : USE CASE LOG APPLICATIF
Déploiement
Inclure les dépendances Spark et celles des sources
Générer un package avec Maven Assembly
Exécution
./bin/spark-submit -- class …
-- master …
-- jars [jar_1,jar_2,…,jar_n]
-- conf p1=v1
….
<app-jar>
[app-arguments]
Configuration
SparkConf.set(“p1”,”v1”)
Dynamique :
-- conf p1=v1
-- conf p2=v2
Config Chargée depuis conf/spark-defaults.conf :
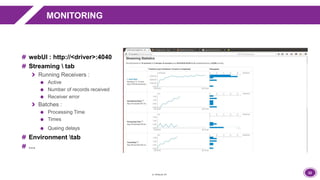
Les propriétés peuvent être consultées depuis la webUI(http://<driver>:4040) # TAB “Environment”](https://image.slidesharecdn.com/barcamppaloit3009-151013150918-lva1-app6892/85/Spark-Streaming-19-320.jpg)
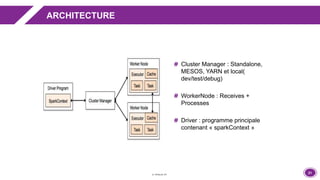









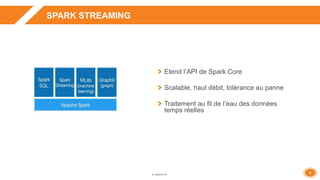
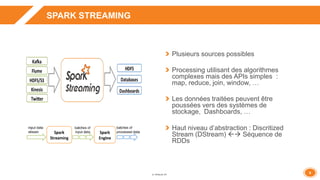
La présentation aborde l'architecture et le fonctionnement de Spark Streaming pour le traitement des données en temps réel, en intégrant des cas d'utilisation concrets comme la gestion des journaux applicatifs et des recommandations statistiques. Elle met en avant la tolérance aux pannes, les options de configuration avec Flume et des recommandations pour le tuning et la performance. Enfin, des démonstrations pratiques illustrent les concepts exposés, accompagnées d'une vue d'ensemble sur des sujets clés comme la gestion de la mémoire et les meilleures pratiques.



























































![[Smile] atelier spark - salon big data 13032018](https://cdn.slidesharecdn.com/ss_thumbnails/smile-atelierspark-salonbigdata13032018-180328084149-thumbnail.jpg?width=640&height=640&fit=bounds)



























