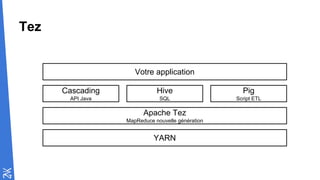
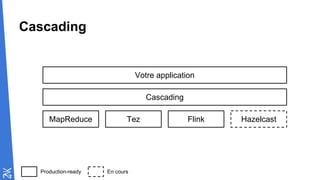
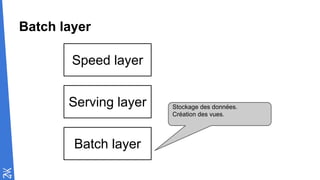
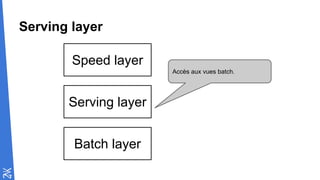
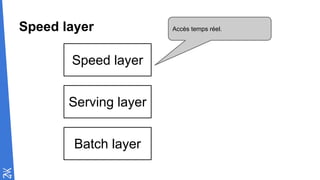
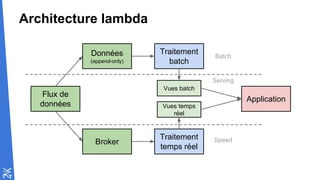
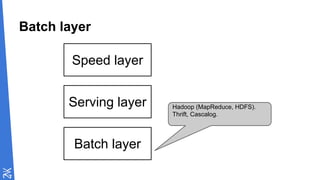
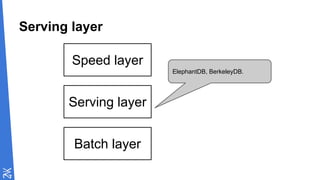
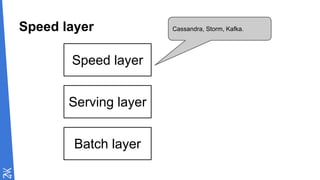
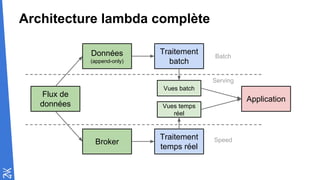
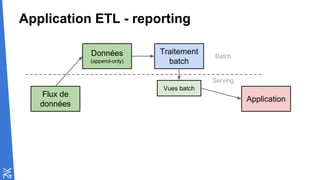
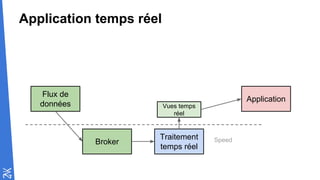
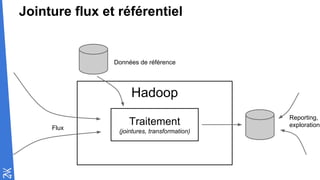
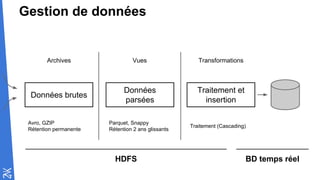
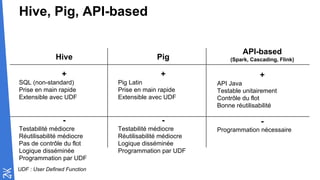
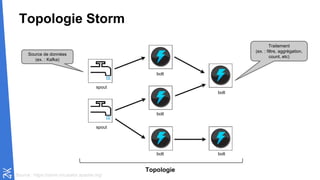
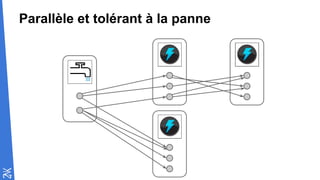
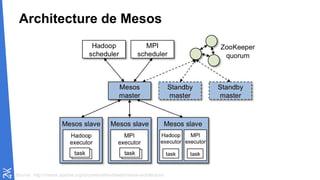
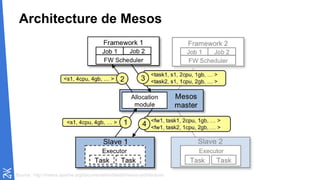
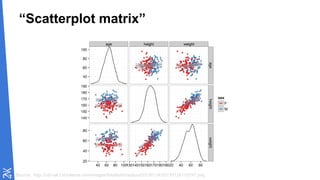
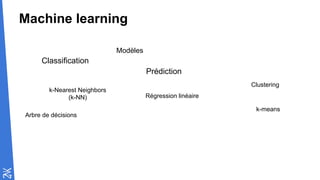
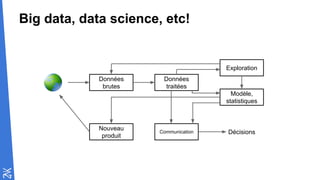
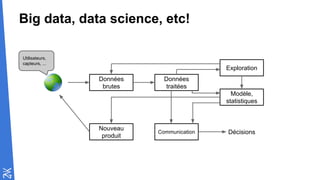
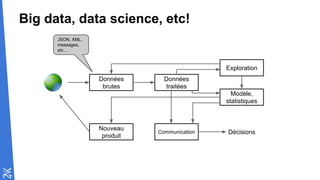
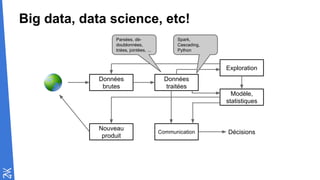
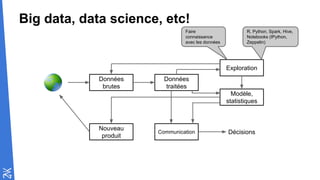
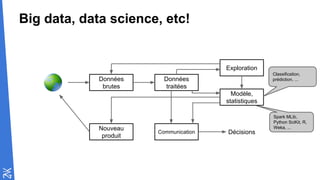
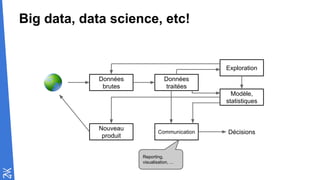
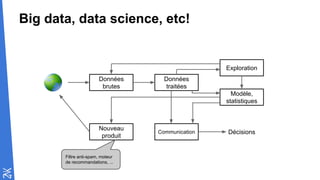
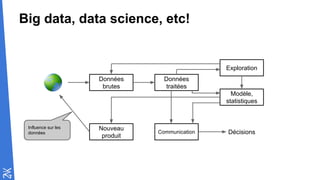
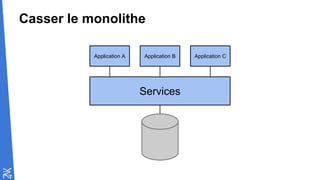
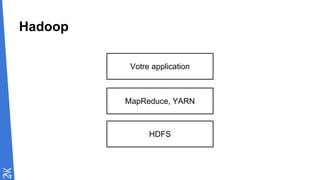
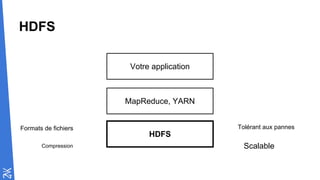
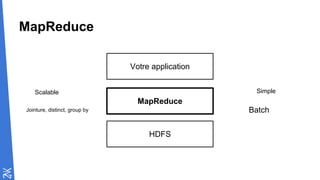
Le document traite des fondamentaux du Big Data, en expliquant des technologies comme Hadoop, MapReduce, et Spark, ainsi que des architectures telles que Lambda. Il aborde les méthodes de traitement des données, l'importance de la tolérance aux pannes, et les stratégies de stockage et de traitement en temps réel. En conclusion, il recommande de considérer le cloud pour le prototypage et de ne pas négliger l'industrialisation du développement.












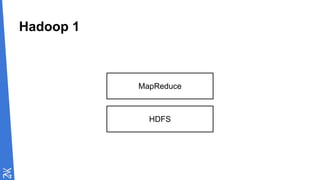
![MapReduce
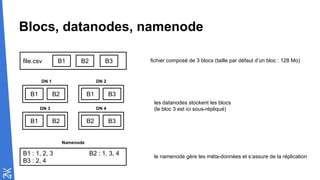
file.csv B1 B2 B3
Mapper
Mapper
Mapper
B1
B2
B3
Reducer
Reducer
k1,v1
k1,v2
k1 [v1,v2]](https://image.slidesharecdn.com/cartographiedubigdata-151113131419-lva1-app6892/85/Cartographie-du-big-data-21-320.jpg)
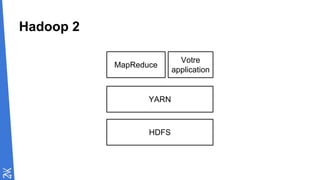
![Le code va à la donnée
file.csv B1 B2 B3
Mapper
Mapper
Mapper
B1
B2
B3
Reducer
Reducer
k1,v1
k1,v2
k1 [v1,v2]
B1 B2 B1 B3
B1 B2 B2 B3
DN 1 DN 2
DN 4DN 3
DN 1
DN 3
DN 4](https://image.slidesharecdn.com/cartographiedubigdata-151113131419-lva1-app6892/85/Cartographie-du-big-data-22-320.jpg)