Téléchargé 32 fois




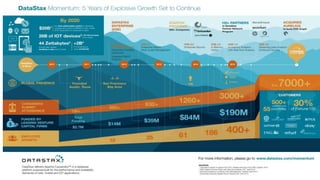

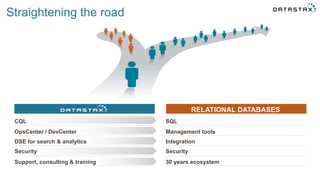





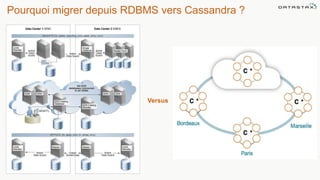
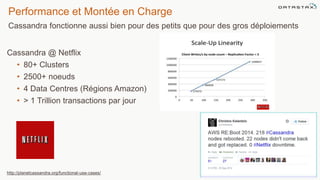

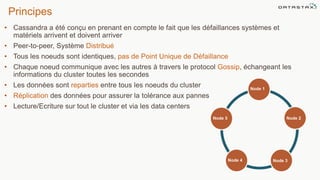
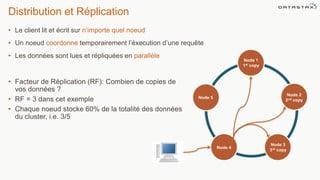
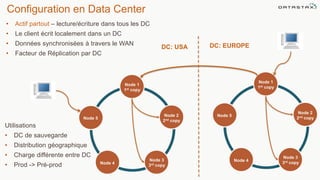
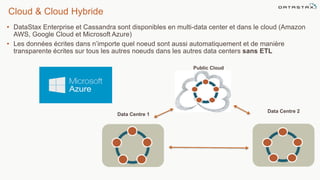
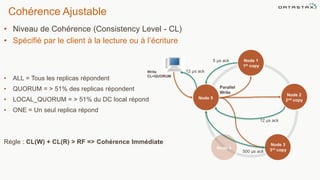
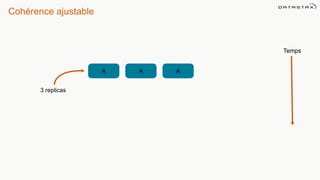
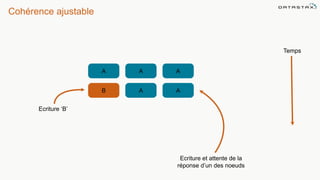
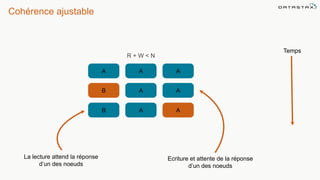
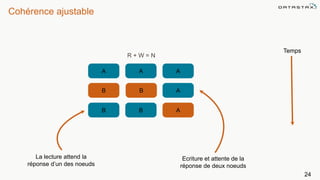
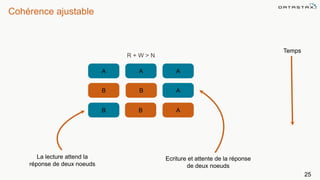
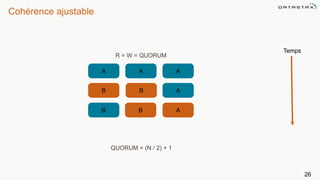
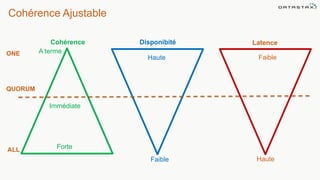
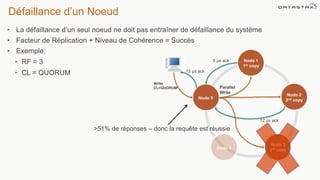










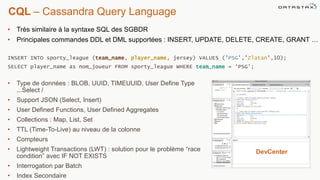



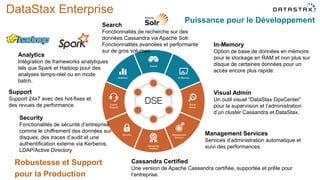
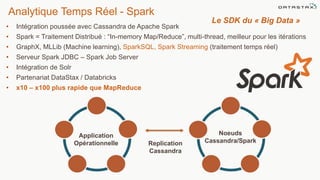
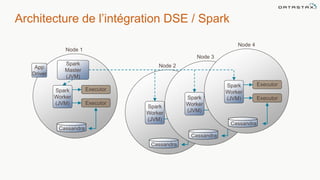
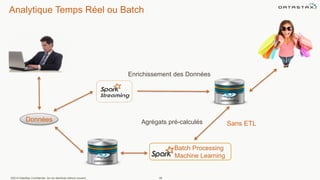
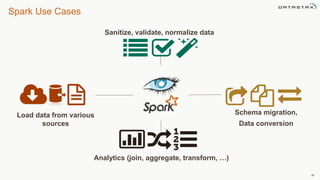
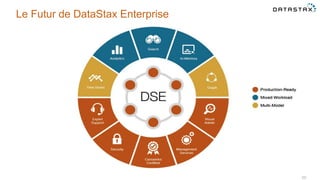

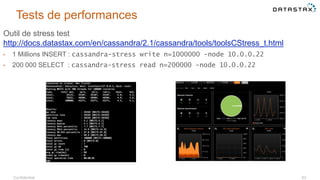





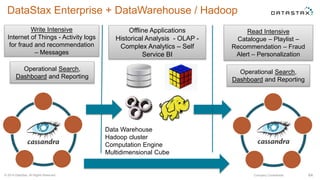
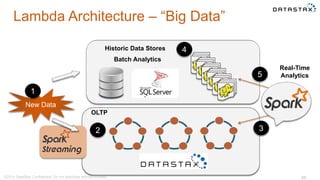




Le document présente des informations sur le déploiement d'Apache Cassandra dans Microsoft Azure, mettant en avant ses fonctionnalités pour les applications modernes avec des besoins de performance et de disponibilité élevés. Il décrit également les principes de fonctionnement de Cassandra, sa capacité à gérer des volumes de données massifs, et propose des outils pour faciliter la gestion et l'analyse des données. Enfin, des démonstrations et des exemples d'application ainsi que des considérations sur la migration depuis les bases de données relationnelles vers Cassandra sont abordés.























![[USI] Lambda-Architecture : comment réconcilier BigData et temps-réel](https://cdn.slidesharecdn.com/ss_thumbnails/preslambdaarch-v3-slideshare-140617091602-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













































