Téléchargé 240 fois





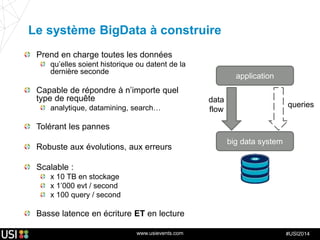

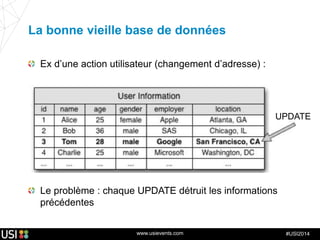





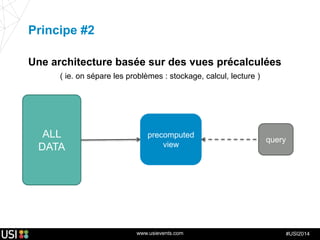
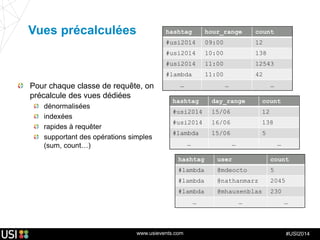
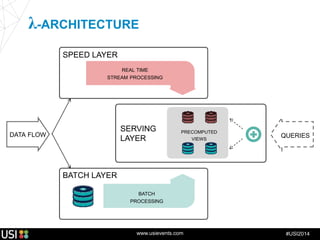

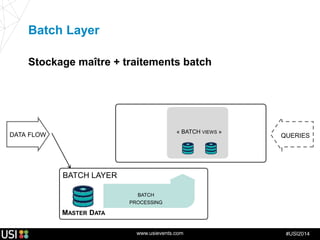


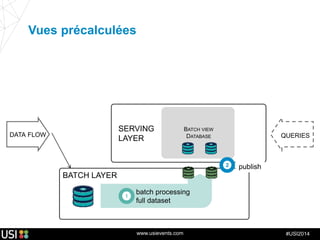

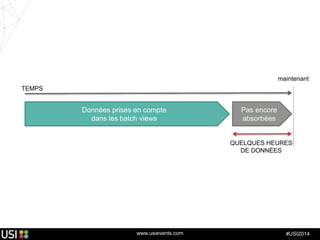

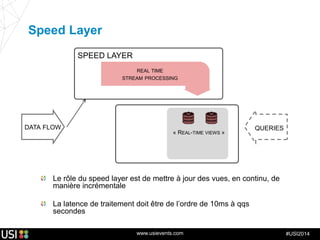

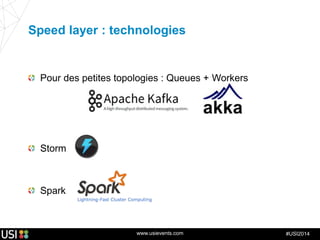
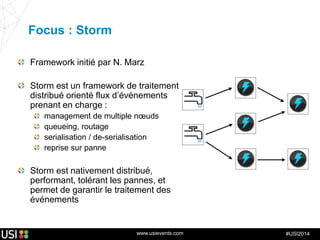
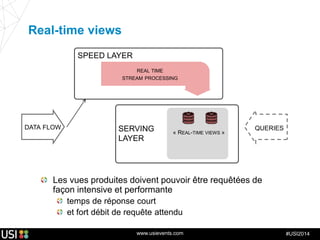


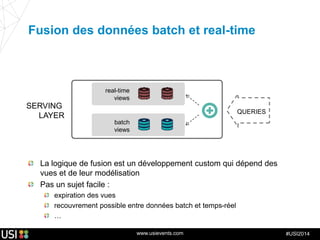
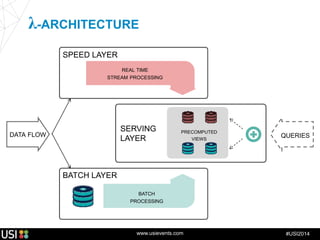


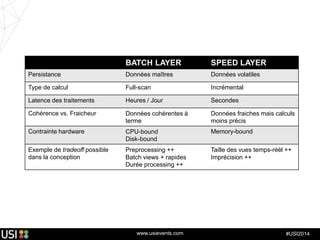


La lambda-architecture est un modèle conçu pour gérer et traiter des flux de big data en temps réel, combinant des données historiques et récentes. Elle se base sur des données immuables et des vues précalculées pour répondre efficacement à des requêtes analytiques, tout en assurant la tolérance aux pannes et la scalabilité. Cette architecture est surtout utilisée dans des cas d'utilisation tels que la recommandation en temps réel, la surveillance d'infrastructures et le traitement des données de l'Internet des objets.























































![[JSS2015] Architectures Lambda avec Azure Stream Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-streamanalytics-151211084144-thumbnail.jpg?width=640&height=640&fit=bounds)











