Téléchargé 44 fois











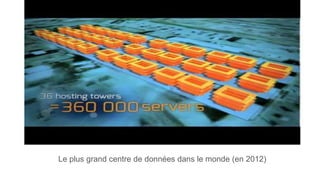




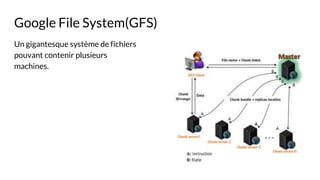
















Le document présente les caractéristiques et l'évolution des big data ainsi que l'importance croissante des bases de données NoSQL comme solution aux défis posés par le volume, la variété et la vélocité des données. Il aborde les approches de gestion des données, notamment MapReduce et différentes catégories de moteurs NoSQL, telles que les moteurs à clé/valeur et orientés document. Enfin, il souligne l'émergence de nouvelles professions liées aux big data, ainsi que les perspectives de marché pour l'avenir de cette technologie.









































































