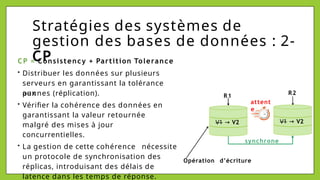
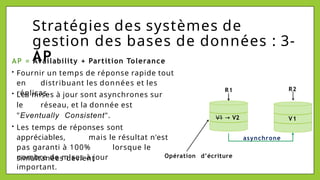
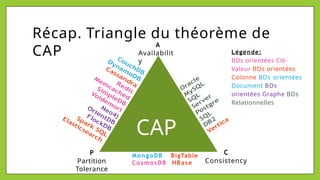
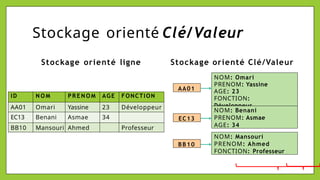
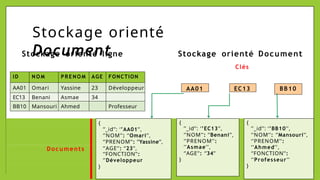
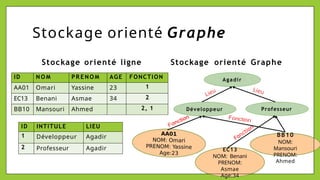
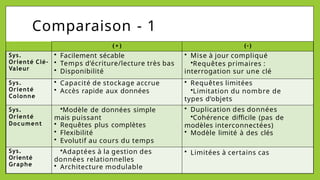
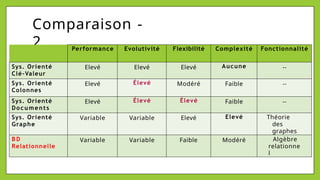
Le document présente les bases de données NoSQL, leurs historiques, défis et types, en contrastant avec les bases de données relationnelles. Il décrit le théorème CAP, qui stipule qu'un système ne peut assurer simultanément cohérence, disponibilité et tolérance aux partitions. Différents modèles de stockage NoSQL, tels que les systèmes orientés clé-valeur, colonne, document et graphe, sont également analysés pour souligner leurs avantages et inconvénients par rapport à un schéma rigide des bases relationnelles.