4
SQL
• Un langagede requête plus ou moins normé.
• Tout information est décrite par des listes de n-uplets
• Opérations puissantes :
– Sélection (where)
– Projection (select)
– Produit cartésien (join)
– Union
– Intersection
– Différence
5.
Transactions ACID
Atomique (Atomic)
•Pas de modification partielle : Une transaction est une unité logique de travail qui
doit être achevée soit avec la totalité de ses modifications de données ou
aucune d'entre elles n'est effectuée.
Cohérente (Consistant)
• A la fin de la transaction, les données doivent être dans un état cohérent.
• Assuré par les contraintes d’intégrités.
• Mais aussi et surtout par le développeur.
Isolées
• Les modifications d’une transaction doivent être indépendantes des autres
transactions : Les modifications ne sont pas visibles par les autres tant que
la transaction n’a pas été validée.
Durable
• Une fois validés, les données sont permanentes jusqu’à leur prochaine modification.
5
6.
6
Marché mature
• Utilisédepuis des dizaines d’années
• De nombreux fournisseurs et de nombreux outils :
– Oracle
– SQL Server
– Mysql
– Postgresql
– MariaDB (clone de Mysql)
– MS Access
7.
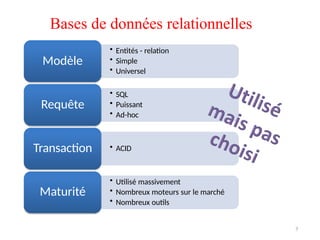
Bases de donnéesrelationnelles
• Entités - relation
• Simple
• Universel
• SQL
• Puissant
• Ad-hoc
• ACID
• Utilisé massivement
• Nombreux moteurs sur le marché
• Nombreux outils
Modèle
Requête
Transaction
Maturité
7
8.
Mise en œuvred’un SGBD-R (1/4)
Base de
données
Serveur Applicatif
HTTP
JDBC
8
9.
Mise en œuvred’un SGBD-R (2/4)
Serveurs
Applicatifs Base de
données
HTTP JDBC
9
10.
Mise en œuvred’un SGBD-R (3/4)
Serveurs
Applicatifs
Base de
données
HTTP JDBC
10
Montée en chargedifficile
• Les règles d’intégrité compliquent la montée horizontale
• Montée en charge verticale
– Coût non linéaire
– Atteint une limite
– Point unique de défaillance
Scalabilité horizontale
difficile
12
13.
13
Coût des transactionsACID
• La lecture est éparpillée
– Lecture d’un panier de N articles
– 2 requêtes
– 2 IO pour lire le panier
– N+1 IO pour les articles
• L’écriture est lente
– IO synchronisés
• La durée d’une requête est difficile à prévoir
– Select * from t where id = ?
– Select * from t where date < (select max(date) from ot)
14.
14
Le modèle EntitéRelation peu exploité
• Le modèle Entité-Relation est souvent peu exploité
• Utilisation du CRUD
• Utilisation de caches
– Memcache
– Ehcache
• Correspondance ORM
– C’est le modèle objet qui est privilégié
15.
15
Limites des SGBDclassiques
• SGBD Relationnels offrent :
– Un système de jointure entre les tables permettant de
construire des requêtes complexes impliquant plusieurs entités.
– Un système d’intégrité référentielle permettant de s’assurer que les liens
entre les entités sont valides.
• Contexte fortement distribué : Ces mécanismes ont un coût considérable :
– Avec la plupart des SGBD relationnels, les données d’une BD liées entre
elles sont placées sur le même nœud du serveur.
– Si le nombre de liens important, il est de plus en plus difficile de placer les
données sur des nœuds différents.
• SGBD Relationnels sont généralement transactionnels ⇒ Gestion
de transactions respectant les contraintes ACID (Atomicity, Consistency,
Isolation, Durability).
16.
16
Limites des SGBDclassiques
• Constat :
– Essor des très grandes plate-formes et applications Web (Google, Facebook,
Twitter, LinkedIn, Amazon,...).
– Volume considérable de données à gérer par ces applications nécessitant une
distribution des données et leur traitement sur de nombreux serveurs.
– Ces données sont souvent associées à des objets complexes et hétérogènes.
⇒ Limites des SGBD traditionnels (relationnels et transactionnels) basés
sur SQL.
⇒ D’où, nouvelles approches de stockage et de gestion des données :
Permettant une meilleure scalabilité dans des contextes fortement
distribués.
Permettant une gestion d’objets complexes et hétérogènes sans avoir à
déclarer au préalable l’ensemble des champs représentant un objet.
Regroupées derrière le terme NoSQL (Not Only SQL), proposé par Carl
Strozzi, ne se substituant pas aux SGBD Relationnels mais les complètant
en comblant leurs faiblesses.
17.
17
Limites des SGBDclassiques
• Nécessaire de distribuer les traitements de données entre différents serveurs.
• Difficile de maintenir les contraintes ACID à l’échelle du système distribué
entier tout en maintenant des performances correctes.
⇒ La plupart des SGBD NoSQL relâchent les contraintes ACID, ou même
ne proposent pas de gestion de transactions.
• BDs NoSQL :
– Ce n’est pas (comme son nom le laisse supposer) NoSQL (pas de SQL).
– Privilégier donc NOSQL plutôt que NoSQL.
• BDsnon-relationnelles et largement distribuées.
• Permet une analyse et une organisation rapides des données de très grands
volumes et de types de données disparates.
• Appelées également :
– Cloud Databases.
– Non-Relational Databases.
– Big Data Databases...
Généralité : Montéeen charge linéaire
• Deux critères
– Volume des données
– Nombre de requêtes
• Twitter
– Janvier 2010 : 50 M/j
– Juin 2011 : 200 M/j
• Le coût doit augmenter linéairement
25
26.
Généralité : Performances- temps d’accès
Il est plus rapide d’interroger une autre machine que de lire
sur le disque local
• 10 ns
Mémoire
• 50 µs
Réseau
local
• 10 ms
Disque
26
27.
27
Généralité : Performancesprédictibles
• La performance des opérations doit être prédictible
• Amazon :
– Perte de 1 %de chiffre d’affaire si le temps
d’affichage des
pages augmente de 0,1 s
– Plan qualité interne : Temps de réponse doit être < 300 ms pour
99,9 % des requêtes pour un pic de 500 requêtes par secondes
• Google pénalise les sites dont les pages s’affichent en plus de
1,5 s
28.
28
Généralité : Priseen compte des pannes
• La panne est la règle
• Amazon :
– Un Datacenter de 100 000 disques.
– Entre 6 000 et 10 000 disques en panne par an.
– (25 disques par jour).
• Les sources de panne sont nombreuses
– Matériel serveur (disque)
– Matériel réseau
– Alimentation électrique
– Anomalies logicielles
– Mises à jour des logiciels et des OS.
29.
Théorème CAP (1/5)
•Après la modification d’une donnée, tous les
clients lisent la nouvelle valeur.
Consistency
(Cohérence)
• Le système répond toujours aux requêtes dans un
temps borné (timeout)
Avalibility
(Disponibilité)
• Le système continue à fonctionner si le réseau
qui relie les nœuds est scindé en deux.
• La chute d’un nœud est une forme
particulière
de partition.
Partition Tolerance
(Tolérance aux
pannes)
29
Théorème CAP
« You can have at most two of these properties for any sharded-data
system. » Eric A. Brewer — 19 juillet 2000
Vous devez comprendre le théorème de la CAP lorsque vous parlez de bases de
données NoSQL ou en fait lors de la conception de tout système distribué.
30.
30
• En théorie,il est impossible de satisfaire à toutes les 3 exigences.
• CAP oblige un système distribué de suivre 2 des 3 exigences.
• Par conséquent, tous les bases de données actuelles
NoSQL
suivent les différentes combinaisons de C, A, P du théorème CAP.
• Voici une brève description des trois combinaisons CA, CP, AP :
– CA – Situés dans un cluster unique, tous les nœuds sont toujours
en contact. Lorsqu'une partition se produit, le système bloque.
– CP - Certaines données peuvent ne pas être accessibles, mais le
reste est toujours conforme/précis.
– AP - Le système est toujours disponible sous le partitionnement,
mais quelques-unes des données renvoyées peuvent être
inexacts/imprécises.
Théorème CAP (2/5)
31.
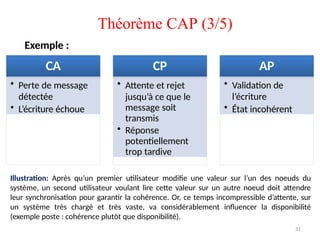
Théorème CAP (3/5)
CA
•Perte de message
détectée
• L’écriture échoue
CP
• Attente et rejet
jusqu’à ce que le
message soit
transmis
• Réponse
potentiellement
trop tardive
AP
• Validation de
l’écriture
• État incohérent
31
Exemple :
Illustration: Après qu’un premier utilisateur modifie une valeur sur l’un des noeuds du
système, un second utilisateur voulant lire cette valeur sur un autre noeud doit attendre
leur synchronisation pour garantir la cohérence. Or, ce temps incompressible d’attente, sur
un système très chargé et très vaste, va considérablement influencer la disponibilité
(exemple poste : cohérence plutôt que disponibilité).
32.
votre compte estl’exemple parfait
32
Théorème CAP (4/5)
Illustration:
• Supposons que soit assuré par réplication consistance et disponibilité, dans le cas
de l’exemple, supposons 2 serveurs de BD dans 2 Data-Centers différents, et que l’on
perde la connexion réseau entre les 2 Data-Centers, faisant que les 2 BD sont
incapables de synchroniser leurs états.
• Si vous parvenez à gérer les opérations de lecture/écriture sur ces 2 BD, il peut être prouvé
que les 2 serveurs ne seront plus consistants.
• Une application bancaire gardant à tout moment l’état de
du problème des enregistrements inconsistants :
-Si un client retire 1000 dinars à Tunis, cela doit
être immédiatement répercuté à Sfax, afin que le système
sache exactement combien il peut retirer à tout .
-Si le système ne parvient pas à le faire,
cela pourrait mécontenter de nombreux
clients.
• Si les banques décident que la consistance est très
importante, et désactivent les opérations d’écriture lors de la
panne, alors la disponibilité du cluster sera perdu puisque
tous les comptes bancaires dans les 2 villes seront désormais
• L'acronyme deBASE a été définie par Eric Brewer, qui est également connu pour
formuler le théorème CAP. Le théorème CAP affirme que tout système à
état partagé en réseau ne peut avoir que deux des trois propriétés
désirables.
• Néanmoins, en gérant explicitement les partitions, les concepteurs
peuvent
optimiser la cohérence et la disponibilité, atteignant ainsi un compromis des trois.
• Propriétés BASE
– Basically Available: le système doit toujours être accessible (ou indisponible
sur de courtes périodes)
– Soft state: l’état de la BD n’est pas garanti à un instant donné (les mises à jour
ne sont pas immédiates : cf. cohérence à terme)
– Eventual consistency: la cohérence des données à un instant donné n’est pas
primordiale (mais assurée à terme : verrouillage optimiste en
reportant à plus tard la vérification de l’intégrité)
BASE
36.
36
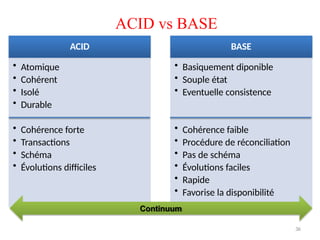
ACID vs BASE
ACID
•Atomique
• Cohérent
• Isolé
• Durable
• Cohérence forte
• Transactions
• Schéma
• Évolutions difficiles
BASE
• Basiquement diponible
• Souple état
• Eventuelle consistence
• Cohérence faible
• Procédure de réconciliation
• Pas de schéma
• Évolutions faciles
• Rapide
• Favorise la disponibilité
Continuum
37.
• Définition
– SGBDnon fondé sur l’architecture des SGBDR, open source, distribué, horizontally
scalable (montée en charge par ajout de serveurs)
• Origine
– « Les SGBDR en font trop, alors que les produits NoSQL font exactement ce dont vous
avez besoin » selon J. Travis (lors de la rencontre meetup NoSQL de San Francisco du
11/6/2009)
– Gestion des BD géantes des sites web de très grande audience
– Exemple des SGBD d’annuaires : grande majorité des accès aux BD consistent en lectures
sans modification (ainsi, seule la persistance doit être vérifiée)
• « Consensus » actuel
– Les SGBD NoSQL ne replacent pas les SGBDR mais les complètent en palliant leurs
faiblesses
• UnQL (Unstructured Query Language)
– 2011 : début d’une spécification d’un langage de manipulation standardisé (pour formaliser
le requêtage des collections des BD NoSQL) 37
SGBD NoSQL (1/3)
38.
• Simplification enrenonçant aux fonctionnalités classiques des SGBDR :
– Redondance (via réplication)
– Pas forcément de schéma normalisé, initialement voire à terme
– Pas de tables mais des collections
– Rarement du SQL (L4G déclaratif, complet au sens de Turing depuis SQL-99)
mais API simple ou langage spécialisé
– Pas forcément de jointure mais multiplication des
requêtes, cache/réplication/données non normalisées, données imbriquées
– Transactions pas forcément ACID mais plutôt BASE
– P s’impose pour un système distribué : AP (accepte de recevoir des données
éventuellement incohérentes) voire CP (attendre que les données
soient cohérentes)
38
SGBD NoSQL (2/3)
39.
• Gestion desmégadonnées (big data) du web, des objets connectés, etc.
• Structure des données hétérogène et évolutive
• Données complexes et pas toujours renseignées
• Environnement distribué : données répliquées et accédées d’un peu partout (dans le monde),
traitement répartis
• Techniques de partionnement des BD : sharding, hachage cohérent (consistent hashing)
• Contrôle de concurrence multi-version (Multi-Version Concurrency Control (MVCC))
– Modification d’une donnée non par écrasement des anciennes données par les nouvelles
mais en indiquant que les anciennes données sont obsolètes et en ajoutant une nouvelle
version (seule la plus récente étant correcte) … ce qui nécessite une purge régulière des
données obsolètes
• Performances linéaires avec la montée en charge (les requêtes obtiennent toujours aussi
rapidement une réponse) 39
SGBD NoSQL (3/3)
40.
• Il existequatre types courants des bases de données NoSQL. Chacune de
ces catégories a ses spécifiques attributs et limites. Il n'y a pas une
solution qui est mieux que tous les autres, mais il y a certaines bases de
données qui sont mieux pour résoudre à certains problèmes.
• Afin de clarifier les bases de données NoSQL, nous discuterons
les
catégories les plus courantes :
– Clef-valeur
– Bases orientées colonnes
– Bases orientées documents
– Graphe
40
NoSQL Catégories - Présentation
41.
• Définition
– BD= 1 tableau associatif unidimensionnel
– Le stockage clé-valeur est le type le plus élémentaire de base de données NoSQL.
– Chaque objet de la base représenté par un couple (clé,valeur) est identifié par une
clé unique qui est le seul moyen d’accès à l’objet
– Les clés sont triées en ordre lexicographique
– Les stockages clé-valeur suivent les aspects CA du théorème CAP.
• Opérations
– Les 4 opérations CRUD :
• create(clé,valeur) : crée un couple (clé,valeur)
• read(clé) : lit une valeur à partir de sa clé
• update(clé,valeur) : modifie une valeur à partir de sa clé
• delete(clé) : supprime un couple à partir de sa clé
– Souvent interface HTTP REST disponible depuis n'importe quel
langage
41
NoSQL Catégories - Clef-valeur (1/6)
42.
• Cas d’utilisation
–Dépôt de masses de données avec des besoins de requêtage simple pour des
analyses en temps-réel: sessions web et fichiers de log, profils utilisateurs,
données de capteurs, gestion de caches, contenu du panier de shopping, valeurs
individuelles comme les couleurs, numéro de compte par défaut, etc.
• Logiciels
– Amazon Dynamo (Riak est l’implémentation open source).
– Redis (projet sponsorisé par VMWare).
– Voldemort (développé par Linkedln en interne puis passage en open source).
– Oracle NoSQL Database
• Types
– Les données de base de données sont stockées comme table de hachage où chaque
clef est unique et la valeur peut être String, Objet sérialisé, BLOB (basic large
object) etc.
– Une clé peut être Strings, Hashes, Lists, Sets, Sorted Sets et les valeurs sont
stockées contre ces clés.
NoSQL Catégories - Clef-valeur (2/6)
43.
Clef Valeur
- Simple/ Répartition facile
-Très performant / Requêtes
optimales à temps constants /
Performances prédictibles
- Disponibilité
-Bonne mise à
l’échelle / Evolutivité des
valeurs
-Convient parfaitement
à l’utilisation d’un cache
- Interrogation seulement sur la clé
- Complexité des valeurs à gérer
dans les programmes
-Pas de requêtes Adhoc ni
filtres complexes
-Toutes les jointures doivent
être faites dans le code
- Pas de contraintes
- Pas de triggers
NoSQL Catégories - Clef-valeur (3/6)
43
Critiques
• Définition
– Donnéesstockées en colonnes.
– C’est une évolution de la BD clé/valeur.
– La colonne est l’entité de base représentant un champ de
donnée, chaque colonne est définie par un couple (clé,valeur)
avec une estampille (pour gérer les versions et les conflits)
− Une super-colonne est une colonne contenant d’autres
colonnes
− Une famille de colonnes regroupe plusieurs colonnes ou supercolonnes où les
colonnes sont regroupées par ligne et chaque ligne est identifiée par un identifiant
unique et par un nom unique
− Les stockages orientés colonnes peuvent améliorer les performances des requêtes
car ils peuvent accéder à des données spécifiques d’une colonne.
− Modèle proche d’une table dans un SGBDR mais ici le nombre de colonnes :
− est dynamique.
− peut varier d’un enregistrement à un autre ce qui évite de retrouver des colonnes
ayant des valeurs NULL.
− Les notions de colonne, super-colonne et famille de colonnes seront détaillées dans
NoSQL Catégories - Orientées colonnes (1/8)
le chapitre suivant « HBase: BD orientée colonne 47
48.
• Opérations
− Lesrequêtes doivent être prédéfinies en fonction de l’organisation en colonnes (et
super-colonnes et familles de colonnes) choisie.
• Cas d’utilisation
– Analyse de données, traitement analytique en ligne (OnLine Analytical Processing
(OLAP)), exploration de données (data mining), entrepôt de données (data
warehouse), gestion de données semi-structurées, jeux de données scientifiques,
génomique fonctionnelle, journalisation d’événements et de compteurs, analyses de
clientèle et recommandation, stockage de listes (messages, posts,
commentaires, ...), traitements massifs
– Ex. : Netflix (logging et analyse de sa clientèle), eBay Inc. (optimisation de la
recherche), Adobe Systems Incorporated (traitement de données structurées et
d’informatique décisionnelle (Business Intelligence (BI))), sociétés de TV
(connaissance de leur audience et gestion du vote des spectateurs)
• Logiciels
– BigTable, HBase, Cassandra, SimpleDB
NoSQL Catégories - Orientées colonnes (2/8)
49.
49
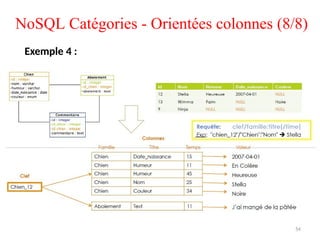
NoSQL Catégories -Orientées colonnes (3/8)
- Bonne mise à l’échelle horizontale.
-Efficace avec l’indexation sur les
colonnes et pour des requêtes temps-réel
connues à l’avance.
-Supporte des données tabulaires à
schéma variable et des données semi-
structurées (facile d’ajouter/fusionner des
colonnes et d’ajouter une colonne/super-
colonne à n’importe quelle ligne d’une
colonne/super-colonne).
- Nombre de colonnes dynamique
(variable d’un enregistrement à un autre
permettant d’éviter les indéterminations)
-Ne supporte pas les
données structurées
complexes ou
interconnectées.
-Maintenance nécessaire pour
la modification de structure en
colonne.
- Ajout de ligne couteux.
- Requêtes doivent être pré-
écrites.
-Toutes les jointures doivent
être faites dans le code
- Pas de contraintes
- Pas de triggers
Critiques
50.
NoSQL Catégories -Orientées colonnes (4/8)
Schéma des données
• Les notions de colonnes et famille de colonnes seront détaillées dans le chapitre
suivant « HBase: BD orientée colonne ».
NoSQL Catégories -Orientées colonnes (7/8)
Une colonne pourrait rassembler plusieurs données stockées dans des lignes
qui s'étendent sur plusieurs tables d'une base de données relationnelle.
53
Exemple 3 :
• Définition
– BD= collection de documents
– Modèle clé-valeur où la valeur est un
document (lisible par un humain) au format
semi-structuré hiérarchique (XML, YAML,
JSON ou BSON, etc.)
– Document (structure
arborescente) = collection de
couples (clé,valeur)
− Un document est un ensemble
de clé-valeur où la clé permet d'accéder à sa
valeur.
− Valeur de type simple ou composée de
plusieurs couples (clé,valeur)
− Les documents ne sont pas généralement forcés d'avoir un schéma. Ils sont donc
flexibles et faciles à modifier.
− Pouvoir de récupérer, via une seule clé, un ensemble d’informations structurées de
55
NoSQL Catégories - Orientées documents (1/6)
56.
• Opérations
− Lesopérations CRUD du modèle clé-valeur
− Souvent interface HTTP REST disponible
− Requêtage (API ou langage) possible sur les valeurs des documents
• Cas d’utilisation
– Outils de gestion de contenu (Content Management System (CMS)), catalogues
de produits, web analytique, analyse temps réel, enregistrement
d’événements, stockage de profils utilisateurs, systèmes d’exploitation, gestion de
données semi- structurées
• Logiciels
– CouchDB, RavenDB, MongoDB, Terrastore
56
NoSQL Catégories - Orientées documents (2/6)
57.
NoSQL Catégories -Orientées documents (3/6)
- Performances élevées
- Bonne mise à l’échelle
-Modèle simple augmenté de
la richesse des documents semi-
structurés.
- Expressivité des requêtes
-Schéma de BD évolutif, efficace
pour les interrogations par clé
-Peut être limité pour les
interrogations par le contenu des
documents.
-Limité aux données
hiérarchiques, inadapté pour les
données interconnectées, baisse
des performances pour de grandes
requêtes.
-Toutes les jointures doivent
être faites dans le code
- Pas de contraintes
- Pas de triggers
Critiques
57
NoSQL Catégories -Orientées documents (6/6)
Exemple 2 :
Un document JSON pourrait, par exemple, prendre toutes les données
stockées dans une ligne qui s'étend sur 20 tables d'une base de données
relationnelle et de les regrouper dans un seul document/objet.
60
61.
• Définition
– Unebase de données de type graphe stocke
les données dans un graphe.
– Elle est basée sur les théories des graphes.
– Elle est capable de représenter élégamment
n'importe quel type de données d'une
manière hautement accessible.
− La gestion d’un graphe (a priori orienté) c.-à-d. la modélisation, le stockage et la
manipulation de données complexes liées par des relations non-triviales
ou variables
− Chaque nœud représente une entité (comme un étudiant ou une entreprise) et
chaque arc représente un lien ou relation entre deux nœuds.
− Quand le nombre de nœuds augmente, le coût d'une étape local (ou hop) reste
le même.
− Conçues pour les données dont les relations sont représentées comme graphes,
et ayant des éléments interconnectés, avec un nombre indéterminé de relations
entre elles.
− Adapté aux traitements des données des réseaux sociaux
61
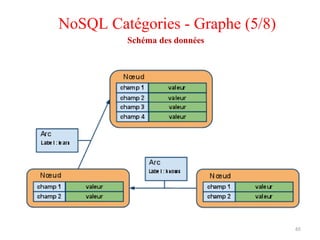
NoSQL Catégories - Graphe (1/8)
62.
• Opérations
− SPARQLpour les SGBD NoSQL Graphe RDF
− API et langages spécialisés de programmation et de requêtes sur les graphes
• Cas d’utilisation
– Moteurs de recommandation, informatique décisionnelle, web sémantique, internet
des objets (internet of things (IoT)), sciences de la vie et calcul scientifique
(bioinformatique, …), données géospatiales, données liées, données hiérarchiques
(catalogue des produits, généalogie, …), réseaux sociaux, réseaux de transport,
services de routage et d’expédition, services financiers (chaîne de financement,
dépendances, gestion des risques, détection des fraudes, …), données ouvertes
(open data)
• Logiciels
– Neo4J, OrientDB, Titan
NoSQL Catégories - Graphe (2/8)
62
63.
Modèle relationnelle
• Tables
•Lignes
• Colonnes
• Jointure
Modèle de graphe
• Ensemble de sommets
et des arêtes.
• Sommets
• Paires clef-valeur
• Arrêtes
63
NoSQL Catégories - Graphe (3/8)
64.
- Modèle richeet évolutif
-Bien adapté aux
situations où il faut
modéliser beaucoup de
relations.
-Nombreux langages et
API bien établis et
performants
- Répartition des données
peut être problématique
pour de gros volumes de
données, fragmentation
(sharding)
NoSQL Catégories - Graphe (4/8)
Critiques
64
69
• Les applicationsinteractives ont beaucoup évolué ces 15 dernières années,
tout particulièrement la gestion des données de ces applications. Le Big
Data, le nombre d'utilisateur croissant (Big Users) et l'architecture Cloud
sont à la source de l'adoption du NoSQL.
• NoSQL s'impose de plus en plus comme une solution alternative viable aux
base de données relationnelles; de plus en plus d'entreprises
reconnaissent que le déploiement d'applications à grande échelle est
meilleure lorsqu'il est fait sur un cluster standard utilisant du matériel
"commodité", et sans schéma de donnée.
Conclusion