Télécharger en tant que PDF, PPTX











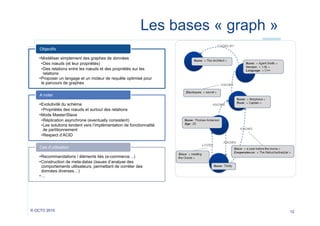

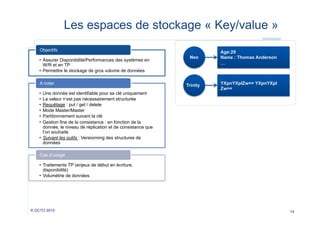

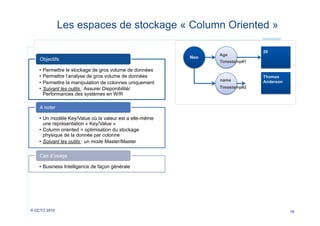







Le document explore les alternatives aux bases de données relationnelles, présentant le mouvement NoSQL comme une réponse aux limitations des SGBDR traditionnels. Il met en avant les avantages tels que la disponibilité, l'élasticité des infrastructures et la gestion de gros volumes de données, tout en soulignant les défis liés à la consistance et aux transactions. Enfin, il décrit différentes catégories de bases NoSQL, incluant des modèles clés/valeurs, documentaires, orientés colonnes et graphiques.






















































































