Télécharger pour lire hors ligne







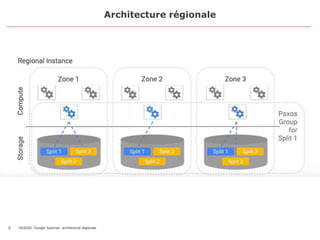











































Le document traite de Google Spanner, une base de données géodistribuée, et de son architecture ainsi que de ses fonctionnalités, en soulignant son rôle dans la gestion des données à l'échelle mondiale. Il décrit les défis auxquels font face les bases de données traditionnelles et comment Google Spanner répond à ces besoins en offrant une architecture résiliente, consistante et scalable garantissant les propriétés ACID. En outre, il aborde les transactions, la conception des bases de données et les bonnes pratiques pour optimiser les requêtes dans Spanner.


































