Téléchargé 255 fois






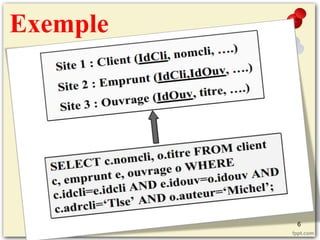















Le document traite des bases de données réparties (BDR) qui sont des ensembles de bases localisées sur différents sites, permettant des transactions locales et globales. Il aborde les motivations, objectifs, conceptions, méthodes de fragmentation et de réplication, et les propriétés essentielles des transactions réparties. En conclusion, les BDR offrent une plus grande autonomie des sites et nécessitent une révision des notions de stockage, de traitement des requêtes et de contrôle d'accès.











































































