
























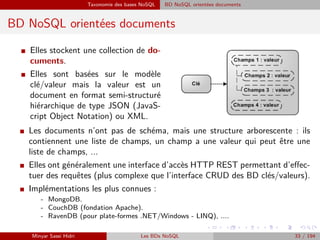

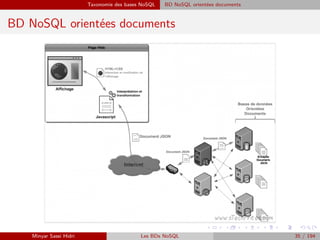











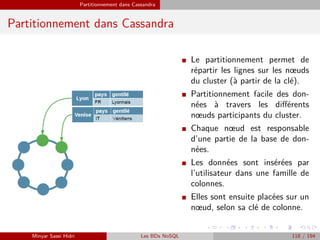
![Technologies communément utilisées dans les bases NoSQL Compromis sur la Cohérence
Gestion de la cohérence
Horloges Vectorielle (Vector Clocks)
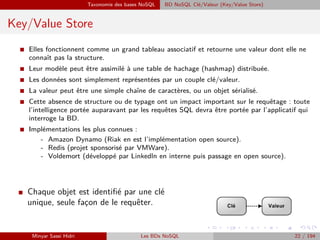
I Les ensembles de données répartis sur nœuds peuvent être lus et modifiés sur chaque
nœud et aucune cohérence stricte est assurée par des protocoles de transactions
distribuées.
Problème : Comment faire des modifications concurrentes ?
I Une solution : les horloges vectorielles : I Un vecteur d’horloge est défini comme un
n-uplet V [0], V [1], ..., V[n] des valeurs
d’horloge à partir de chaque nœud.
I À tout instant le nœud i maintient un vec-
teur d’horloge représentant son état et ce-
lui des autres nœuds répliques : (Vi [0] =
valeur de l’horloge du premier nœud, Vi [1]
= valeur de l’horloge du deuxième nœud,
... Vi [i] = sa propre valeur d’horloge, ... Vi
[n] = valeur de l’horloge du dernier nœud).
I Les valeurs d’horloge peuvent être de
réelles timestamps dérivées d’une hor-
loge locale de nœud, du numéro de ver-
sion/révision, etc.
Minyar Sassi Hidri Les BDs NoSQL 54 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-54-320.jpg)














![L’invite interactive de MongoDB Lecture/´Ecriture
Insertion de documents
I Pour insérer un document dans une collection (que la collection existe ou non) :
>db.collection.insert(document)
>db.collection.insert(documents)
- document est un tableau clefs / valeurs.
- documents est une liste de tableaux clefs / valeurs.
- collection est le nom de la collection à laquelle on souhaite ajouter le(s) document(s). Si la collection n’existait
pas au préalable, elle est créée (c’est de cette manière qu’on crée les collections).
>db.etudiants.insert({’prenom’ : ’Camille’,’nom’ : ’Simon’})
>db.etudiants.insert({ ’prenom’ : ’Thomas’ })
>db.etudiants.insert([ { ’prenom’ : ’Jordan’ },
{ ’prenom’ : ’Mélanie’} ] )
>db.etudiants.insert([ {’prenom’ : ’Camille’,’nom’ : ’Alberti’},
{’prenom’ : ’Laura’,’nom’ : ’Seban’}])
>db.cours.insert([{ ’code’ : ’IO2’, ’intitulé’ : ’Internet et outils’ },
{ ’code’ : ’TO2’, ’intitulé’ : ’Types de données et objets’}])
Minyar Sassi Hidri Les BDs NoSQL 74 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-74-320.jpg)
![L’invite interactive de MongoDB Lecture/´Ecriture
Recherche
Fonction find() (1)
I Exemple :
>db.etudiants.find()
>db.etudiants.find({ ’prenom’ : ’Camille’})
I Résultat :
> db.etudiants.find( { ’prenom’ : ’Camille’ } )
{ ” id” : ObjectId(”532d40c72d150b4635b8cfc9”), ”prenom” : ”Camille”, ”nom” : ”Simon” }
{ ” id” : ObjectId(”532d40c72d150b4635b8cfcd”), ”prenom” : ”Camille”, ”nom” : ”Alberti” }
- Le champ id a été ajouté par le système au moment de l’opération insert. On peut ensuite l’utiliser pour
désigner un document précis :
> db.etudiants.find({ id : ObjectId(”532d40c72d150b4635b8cfc9”) })
{ ” id” : ObjectId(”532d40c72d150b4635b8cfc9”), ”prenom” : ”Camille”, ”nom” : ”Simon” }
I Le résultat renvoyé par find est un curseur, un objet qui permet d’itérer sur les documents.
Considérons un exemple d’utilisation simple, comme un tableau :
> var c = db.etudiants.find({’prenom’ : ’Camille’})
> c[0]
{
” id” : ObjectId(”532d40c72d150b4635b8cfc9”),”prenom” : ”Camille”,”nom” : ”Simon”}
> c[0].nom
Simon
Minyar Sassi Hidri Les BDs NoSQL 76 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-76-320.jpg)
![L’invite interactive de MongoDB Lecture/´Ecriture
Recherche
Fonction find() (2)
I On peut également utiliser l’opérateur $or pour indiquer un OU logique, sur le modèle :
>db.collection.find({$or : [ {field1 : value1},{field2 :value2}]})
I Plutôt que d’indiquer une valeur fixe dans ces instructions conditionnelles, on peut
également utiliser des opérateurs tel que supérieur à, inférieur à, etc.. ils respectent la
syntaxe suivante :
{field : {operator :value}}
I Et on dispose des opérateurs suivantes :
- $gt : plus grand que.
- $gte : plus grand ou égal a.
- $lt : plus petit que.
- $lte : plus petit ou égal a.
- $ne : different de.
Minyar Sassi Hidri Les BDs NoSQL 77 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-77-320.jpg)
![L’invite interactive de MongoDB Lecture/´Ecriture
Recherche
Fonction find() (3)
I On peut également indiquer, par le biais d’un second argument à find(),
quels champs on souhaite sélectionner. Si ce second argument n’est pas
spécifié, tous les champs du document sont renvoyés.
.find({...},{field1 :[0|1],field2 :[0|1],...})
I Pour sélectionner tous les élèves mais sans extraire leurs noms et prénoms :
>db.eleves.find({}, {prenom :0,nom :0})
I On peut également appliquer un équivalent de l’opérateur limit par le biais
des fonctions limit() et skip() à appliquer respectivement à find() et à
limit().
- pour sélectionner les N premiers documents : .find(...).limit(N).
- pour sélectionner les N premier documents à partir du Mième document :
.find(...).limit(N).skip(M).
Minyar Sassi Hidri Les BDs NoSQL 78 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-78-320.jpg)
![L’invite interactive de MongoDB Lecture/´Ecriture
Recherche
Fonction find() (4)
I On peut également trier les documents résultant de notre recherche. Pour ce
faire, on va utiliser la fonction .sort() à appliquer à find().
.find(...).sort({field1 :[1|-1], filed2 :[1|-1],...)
...où 1 désigne un ordre ascendant et -1 un ordre descendant.
I Un autre opérateur utilisable au sein des instructions conditionnelles est
l’opérateur in.
{filed : {in : [value1, value2, value3,...]}}
Minyar Sassi Hidri Les BDs NoSQL 79 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-79-320.jpg)
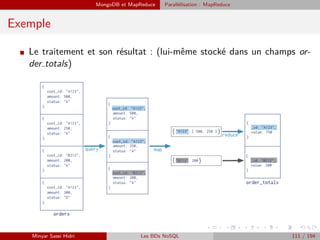
![L’invite interactive de MongoDB Exemple
Exemple
Insertion des données dans MongoDB (2)
I Nous commenc¸ons par ajouter les éditeurs :
>show dbs
>use bibliotheque
>db.editeurs.insert({ nom : ”Hachette”}) ;
>db.editeurs.insert({ nom : ”Hatier”}) ;
>db.editeurs.insert({ nom : ”O’Reilly”}) ;
I Consultons le contenu de la collection editeurs :
> db.editeurs.find({})
I On a bien ajouté trois documents dans la collection editeurs. On remarque que MongoDB
a automatiquement ajouté un identifiant. On peut maintenant ajouter les documents livres
en reprenant les Id des éditeurs.
> db.livres.insert({type : ”livre”, titre : ”Aubonheurdesdames”, annee : 2010, editeur :
new DBRef ( editeurs , ObjectId(”4fa40cbe9ff 7ba90f 5d13eed”)), ISBN : ”2012814557”,
auteurs : [{nom : ”Zola”, prenom : ”Emile”}]});
> db.livres.insert({type : ”livre”, titre : ”Germinal”, annee : 1995, editeur : newDBRef ( editeurs ,
ObjectId(”4fa40d359ff 7ba90f 5d13eee”)),
format : ”Poche”, auteurs : [{nom : ”Zola”, prenom : ”Emile”}]});
> db.livres.insert({type : ”livre”, titre : ”TheDefinitiveGuidetoMongodb”, annee : 2003,
editeur : newDBRef ( Editeurs , ObjectId(”4fa40dfb7b071ce946d6dc34”)),
ISBN : ”1449381561”, pages : 206, langue : ”Anglais”,
auteurs : [{nom : ”Dirolf ”, prenom : ”Michael”}, {nom : ”Dirolf ”, prenom : ”Kristina”}]});
I Vérification du nombre de livres en base :
>db.livres.count()
Minyar Sassi Hidri Les BDs NoSQL 83 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-83-320.jpg)

















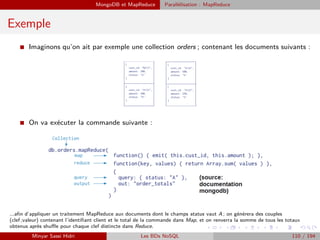














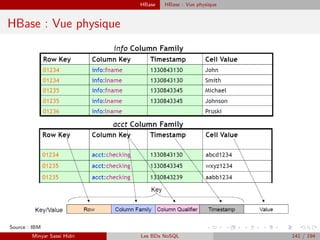
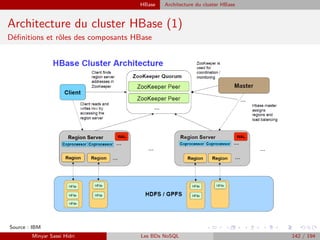

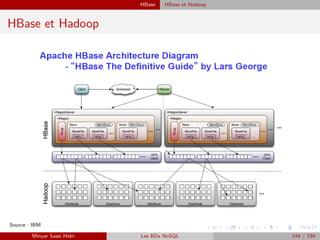


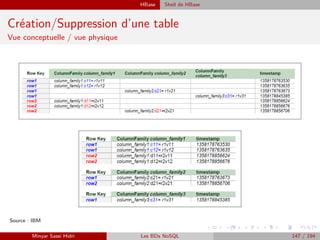
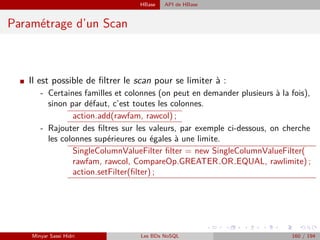
![HBase Recherche de n-uplets
Recherche de n-uplets
I La commande scan affiche les n-uplets sélectionnés par les conditions. La difficulté, c’est
d’écrire les conditions en Ruby.
Scan ’NOMTABLE’, {CONDITIONS}
I Conditions :
- COLUMNS=>[’FAMILIY COLUMN :COLONNE’,...] pour sélectionner certaines co-
lonnes.
- STARTROW=>’CLE1’, STOPROW=>’CLE2’ pour sélectionner les n-uplets entre
CLE1 et CLE2.
- VERSIONS=>NB affiche NB versions des valeurs.
- FILTER=>”ValueFilter(OP, ’binary :CONSTANTE’)” permet de comparer les valeurs
à une constante, mettre <, <=, =, ! =, >, >= pour OP. Il existe quelques autres
filtres.
- ....
Scan ’table 1’, {FILTER => ”ColumnPrefixFilter (’d11’)”}
I Voici comment compter les n-uplets d’une table, en configurant le cache pour en prendre
1000 à la fois :
Count ’NOMTABLE’, CACHE => 1000
I HBase n’est qu’un stockage de mégadonnées. Il n’a pas de dispositif d’interrogations so-
phistiqué.
Minyar Sassi Hidri Les BDs NoSQL 149 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-149-320.jpg)
![HBase API de HBase
Création/ Suppression d’une table
I Voici une fonction qui crée une table :
void CreerTable(String nomtable, String[] familles)
{
Configuration config = HBaseConfiguration.create() ;
HBaseAdmin admin = new HBaseAdmin(config) ;
try {TableName tn = TableName.valueOf(nomtable) ;
HTableDescriptor htd = new HTableDescriptor(tn) ;
for (String famille : familles) {
htd.addFamily(new HColumnDescriptor(famille)) ;
}
admin.createTable(tabledescriptor) ;
} finally {
admin.close() ;
}
}
I Voici comment on supprime une table, en vérifiant au préalable si elle existe :
void SupprimerTable(String nomtable)
{
Configuration conf = HBaseConfiguration.create() ;
HBaseAdmin admin = new HBaseAdmin(conf) ;
try {TableName tn = TableName.valueOf(nomtable) ;
if (admin.tableExists(tn)) {
admin.disableTable(tn) ;
admin.deleteTable(tn) ;
}
}finally {
admin.close() ;
}
}
Minyar Sassi Hidri Les BDs NoSQL 151 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-151-320.jpg)

![HBase API de HBase
Insertion d’une valeur
Transformation en tableaux d’octets
I L’insertion d’une valeur consiste à créer une instance de la classe Put. Cet
objet spécifie la valeur à insérer :
- identifiant du n-uplet auquel elle appartient
- nom de la famille
- nom de la colonne
- valeur
- en option, le timestamp à lui affecter.
I Toutes les données concernées doivent être converties en tableaux d’octets.
I Transformation en tableaux d’octets :
- HBase stocke des données binaires quelconques : chaînes, nombres, images jpg, etc.
Il faut seulement les convertir en byte[].
- Convertir une donnée en octets se fait quelque soit son type par :
final byte[] octets = Bytes.toBytes(donnée) ;
Minyar Sassi Hidri Les BDs NoSQL 153 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-153-320.jpg)
![HBase API de HBase
Insertion d’une valeur (fonction)
void AjouterValeur(String nomtable, String id, String fam, String col, String val)
{
Configuration config = HBaseConfiguration.create() ;
HTable table = new HTable(config, nomtable) ;
// Construire un Put
final byte[] rawid = Bytes.toBytes(id) ;
Put action = new Put(rawid) ;
final byte[] rawfam = Bytes.toBytes(fam) ;
final byte[] rawcol = Bytes.toBytes(col) ;
final byte[] rawval = Bytes.toBytes(val) ;
action.add(rawfam, rawcol, rawval) ;
// Effectuer l’ajout dans la table
table.put(action) ;
}
Minyar Sassi Hidri Les BDs NoSQL 155 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-155-320.jpg)
![HBase API de HBase
Extraction d’une valeur
I La récupération d’une cellule fait appel à un Get.
I Il se construit avec l’identifiant du n-uplet voulu.
I Ensuite, on applique ce Get à la table. Elle retourne un Result conte-
nant les cellules du n-uplet.
static void AfficherNuplet(String nomTable, String id)
{
final byte[] rawid = Bytes.toBytes(id) ;
Get action = new Get(rawid) ;
// appliquer le get à la table
Configuration config = HBaseConfiguration.create() ;
HTable table = new HTable(config, nomTable) ;
Result result = table.get(action) ;
AfficherResult(result) ;
}
Minyar Sassi Hidri Les BDs NoSQL 156 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-156-320.jpg)
![HBase API de HBase
Extraction d’une valeur
Résultat d’un Get
I Un Result est une sorte de dictionnaire (famille, colonne) → valeur.
- Sa méthode getValue(famille, colonne) retourne les octets de la valeur
désignée, s’il y en a une :
byte[] octets = result.getValue(rawfam, rawcol) ;
- On peut parcourir toutes les cellules par une boucle :
void AfficherResult(Result result)
{
for (Cell cell : result.listCells())
{
AfficherCell(cell) ;
}
}
Minyar Sassi Hidri Les BDs NoSQL 157 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-157-320.jpg)
![HBase API de HBase
Parcours des n-uplets d’une table
I Réaliser un Scan par programme n’est pas très compliqué.
I Il faut fournir la clé de départ et celle d’arrêt (ou alors le scan se fait
sur toute la table). On reçoit une énumération de Result.
void ParcourirTable(String nomtable, String start, String stop)
{
final byte[] rawstart = Bytes.toBytes(start) ;
final byte[] rawstop = Bytes.toBytes(stop) ;
Scan action = new Scan(rawstart, rawstop) ;
Configuration config = HBaseConfiguration.create() ;
HTable table = new HTable(config, nomTable) ;
ResultScanner results = table.getScanner(action) ;
for (Result result : results) {
AfficherResult(result) ;
}
}
Minyar Sassi Hidri Les BDs NoSQL 159 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-159-320.jpg)

![Neo4j
Neo4j : Exemple (1)
I Tout d’abord, nous créons un nœud :
CREATE n = {nom : ’Milou’, ville : ’Paris’} ;
I Affichage :
START n=node(1) RETURN n ;
I Résultat :
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> | n |
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> | Node[1]{nom : Milou ,ville : Paris } |
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> 1 row
==> 0 ms
Minyar Sassi Hidri Les BDs NoSQL 163 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-163-320.jpg)
![Neo4j
Neo4j : Exemple (2)
I Nous allons maintenant ajouter un deuxième nœud et une relation dans
la même commande :
START Milou = node(1)
CREATE
Tintin = { nom : ’Tintin’, ville : ’Paris’ },
Milou-[r :AMI]->Tintin
RETURN
Tintin ;
I Ce qui retourne :
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> | Tintin |
==> +————————————-+
==> | Node[2]{nom : Tintin ,ville : Paris } |
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> 1 row
==> Nodes created : 1
==> Relationships created : 1
==> Properties set : 2
==> 42 ms
==>
Minyar Sassi Hidri Les BDs NoSQL 164 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-164-320.jpg)
![Neo4j
Neo4j : Exemple (3)
I `A l’aide de la commande START, nous avons indiqué le point de départ de notre pattern, c’est-à-dire de notre instruction.
I Nous avons ensuite créé un nœud et une relation que nous avons nommée AMI.
I Ajoutons encore quelques nœuds :
START Milou = node(1), Tintin = node(2)
CREATE
Haddock = { nom : ’Capitain Haddock’, ville : ’Moulinsart’},
Castafiore = { nom : ’Castafiore’, ville : ’Pesaro’},
Tintin-[r :AMI]->Haddock,
Haddock -[r :AMI]->Castafiore ;
I Les relations, comme les nœuds, sont numérotées. Nous pouvons maintenant appliquer toutes sortes de requêtes pour
traverser l’arbre et chercher les relations.
I Exemple : la requête suivante cherche s’il y a une relation de type AMI entre Milou et la Castafiore :
START Milou=node(1), Castafiore=node(4)
MATCH Milou[r :AMI*]->Castafiore
RETURN r ;
I La requête peut se lire ainsi : pour Milou et la Castafiore, s’il y a une relation de type AMI qui va de Milou à la Castafiore
en passant par un nombre indéfini (*) de relations intermédiaires, retourne-moi cette relation. Le résultat est :
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> | r |
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> | [ :AMI[2] {}, :AMI[1] {}, :AMI[0] {}] |
==> +-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−-−+
==> 1 row
==> 4 ms
I Bibliothèques clientes pour différents langages.
I Le client pour Python s’appelle py2neo.
Minyar Sassi Hidri Les BDs NoSQL 165 / 194](https://image.slidesharecdn.com/nosql-161213143036/85/Les-BD-NoSQL-165-320.jpg)



















Le document traite des bases de données NoSQL, en expliquant leur émergence face aux limitations des systèmes de gestion de bases de données relationnelles classiques dans le contexte du Big Data. Il présente différents types de bases NoSQL, comme celles orientées clés/valeurs, colonnes, documents et graphes, tout en abordant leurs avantages et inconvénients, ainsi que les principes du théorème de CAP. Enfin, il souligne l'importance de ces bases pour la scalabilité et la gestion de données complexes dans des systèmes distribués.


































































