Télécharger en tant que PDF, PPTX









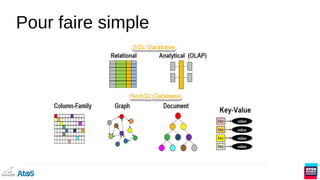
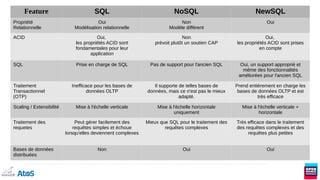





![Ex : Blob : Colonnes dynamiques
create table newsql(
id int
auto_increment
primary key,
nom varchar(40),
type enum
('animal',
'ordinateur'),
prix int,
nosql blob);
COLUMN_CREATE(
column_nr,
value [as type],
[
column_nr,
value [as type]
],
...)](https://image.slidesharecdn.com/mariadb-newsql-221113153025-6d50ed17/85/MariaDB-une-base-de-donnees-NewSQL-17-320.jpg)





![Ex : Documents
set @json='
[
{"name":"Laptop", "color":"black", "price":"1000"},
{"name":"Jeans", "color":"blue"}
]';
select * from json_table(@json, '$[*]'
columns(
name varchar(10) path '$.name',
color varchar(10) path '$.color',
price decimal(8,2) path '$.price' )
) as jt;
+--------+-------+---------+
| name | color | price |
+--------+-------+---------+
| Laptop | black | 1000.00 |
| Jeans | blue | NULL |
+--------+-------+---------+](https://image.slidesharecdn.com/mariadb-newsql-221113153025-6d50ed17/85/MariaDB-une-base-de-donnees-NewSQL-23-320.jpg)



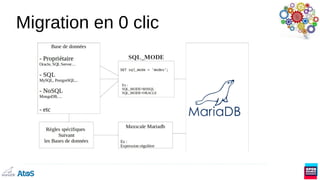

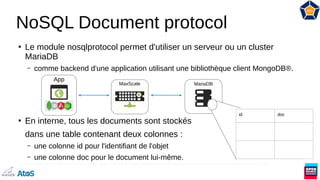


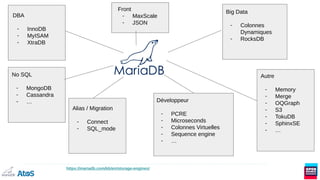
Le document présente une vue d'ensemble des systèmes de gestion de bases de données NewSQL, qui combinent les propriétés des bases de données relationnelles (ACID) et non relationnelles (NoSQL) en offrant une évolutivité horizontale. Il aborde l'importance des moteurs de stockage et les différents modèles de données, y compris le JSON et les bases de données en colonnes. Enfin, il explique l'historique de MariaDB et ses évolutions vers des solutions interopérables prenant en charge divers types de données.



































































