Télécharger pour lire hors ligne





















![RECHERCHE - REQUÊTE
POST /index/document/_search
{
"query": {
"filtered": {
"query": {
"query_string": {
"fields": [
"title^5",
"description^2",
"content"
],
"query": "moteur de recheche en ruby",
"fuzzy_prefix_length": 2,
"fuzziness": 1
}
},
"filter": {
"bool": {
"must": [
{
"match": {
"rights": "public"
},
"should": {
"types": "article"
}
}
]
}
}
}
}
}](https://image.slidesharecdn.com/clermontechapihour22adopteunebdd-161014151023/85/Adopte-une-BDD-32-320.jpg)
![RECHERCHE – RÉSULTAT AVEC SCORING
{
"hits": {
"total": 2,
"max_score": 0.11843335,
"hits": [
{
"_index": “index",
"_type": “document",
"_id": "1",
"_score": 0.30052114,
"_source": {
“title": "adopte un moteur de recherche"
}
},
{
"_index": " index ",
"_type": " document ",
"_id": "2",
"_score": 0.038161416,
"_source": {
“title": "adopte le language ruby"
}
}
]
}
}](https://image.slidesharecdn.com/clermontechapihour22adopteunebdd-161014151023/85/Adopte-une-BDD-33-320.jpg)


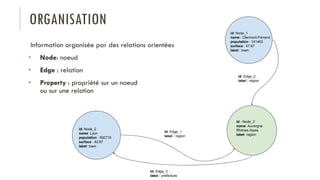
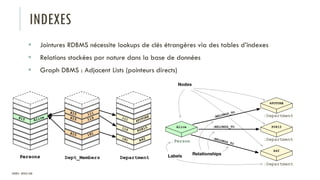




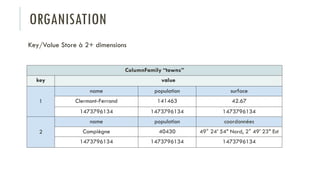



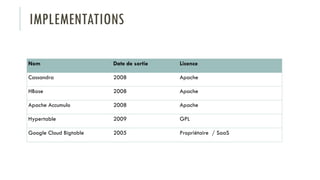




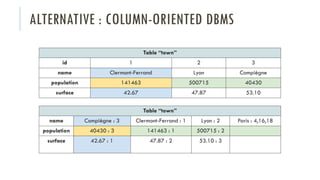


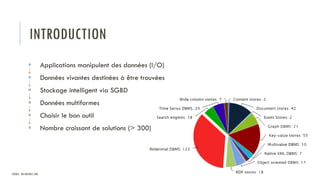
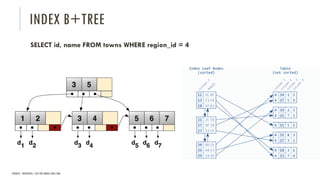
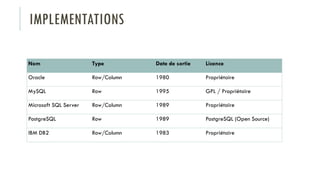
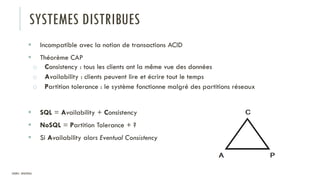
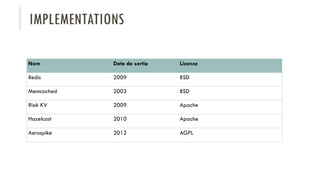
Le document discute des différents types de bases de données, y compris les systèmes de gestion de base de données relationnels, NoSQL, moteurs de recherche et bases de données graphiques, ainsi que leurs applications, avantages et inconvénients. Il aborde également les concepts comme les transactions ACID, la scalabilité, et les cas d'utilisation spécifiques de chaque type de base de données. Enfin, il souligne l'évolution vers les bases de données multi-modèles pour répondre à des exigences variées en performance et volumétrie.
















































