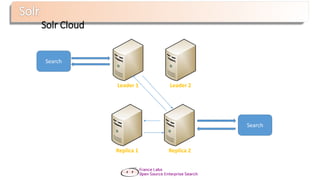
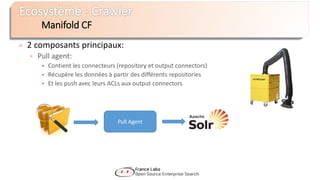
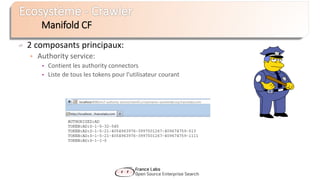
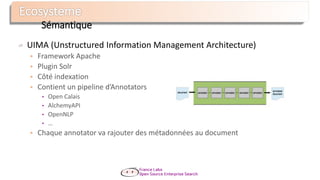
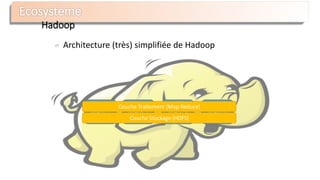
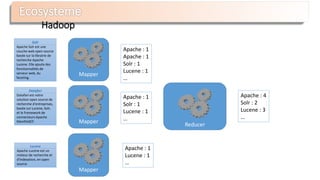
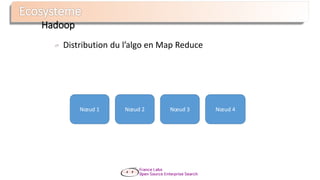
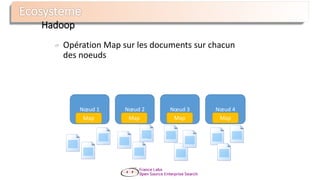
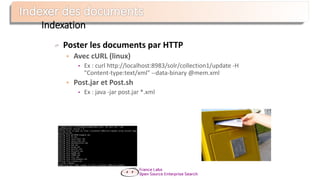
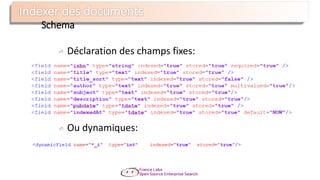
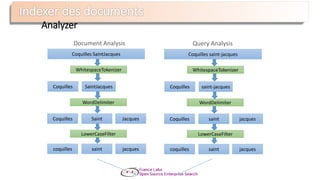
Le document présente Apache Solr, une bibliothèque de recherche open source basée sur Lucene, utilisée pour créer des moteurs de recherche d'entreprise. Il aborde les avantages de Solr, son architecture, ses fonctionnalités et la nécessité d'un serveur pour l'utiliser efficacement. De plus, il traite des concepts de scoring, d'indexation, et de recherche distribuée au sein de Solr Cloud.














![Lucene
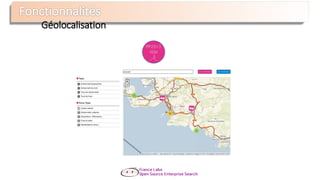
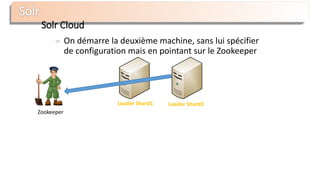
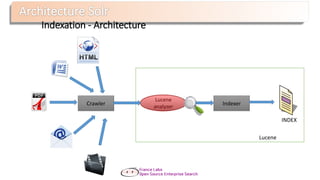
Requêtage - Architecture
Query
Parser
Lucene
analyzer
Index
Searcher
type:voitures AND prix:[3000 TO 5000]
INDEX](https://image.slidesharecdn.com/nantesjug-150218033658-conversion-gate01/85/Presentation-Lucene-Solr-Datafari-Nantes-JUG-18-320.jpg)




























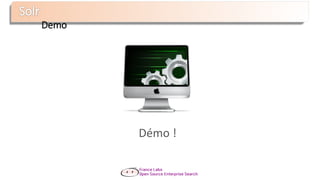
![Type de requêtes
Type But Exemple
TermQuery
Simple terme
Peut être spécifique à un
champ
Tarte
Type:Dessert
PhraseQuery
Match de plusieurs
termes dans l’ordre
« tarte aux pommes"
RangeQuery Fourchette
[A TO Z]
{A TO Z}
WildcardQuery Lettres manquantes
j*v?
f??bar
PrefixQuery
Tous les termes qui
commencent par X.
cheese*
FuzzyQuery Distance de Levenshtein manger~
BooleanQuery
Agrégation de plusieurs
queries
manger AND
cheese* -cheesecake](https://image.slidesharecdn.com/nantesjug-150218033658-conversion-gate01/85/Presentation-Lucene-Solr-Datafari-Nantes-JUG-58-320.jpg)