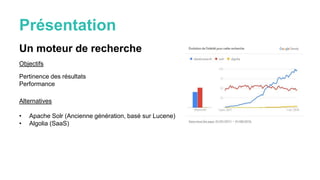
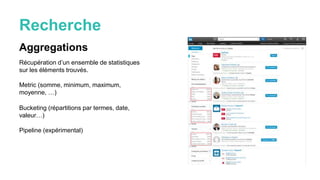
Le document présente Elasticsearch, un moteur de recherche basé sur une architecture distribuée et une API RESTful, permettant des recherches avancées grâce à des concepts comme les clusters, les nœuds et les shards. Il couvre également les types de requêtes, les filtres, et des fonctionnalités supplémentaires telles que les agrégations et les suggestions. Enfin, des ressources et des outils pour approfondir la compréhension d'Elasticsearch sont fournis.