Le document présente Elastic Stack, incluant Elasticsearch, Logstash et Kibana, en mettant en avant les avantages d'Elasticsearch comme un moteur de recherche open source performant et scalable. Il décrit les concepts de base tels que les documents, les indices et les shards, ainsi que les fonctionnalités d'installation et de mapping. Enfin, le document compare Elasticsearch à Hadoop et explique l'utilisation de Logstash et Kibana pour le traitement et la visualisation des données.








![Document
Document : Un simple enregistrement dans un shard Elasticsearch.
Un document est structuré comme un objet JSON et doit appartenir à
un type (qui défini sa structure).
Exemple d'un document de type Ville
8
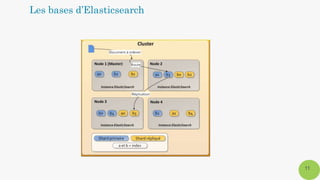
Les bases d’Elasticsearch
{
"title" : "Star Wars",
"directors" : ["George Lucas"],
"release_date" : "1977-05-25T00:00:00Z",
"rating" : 8.7,
"genres" : ["Action","Adventure","Fantasy","Sci-Fi"],
"plot" : "Luke Skywalker joins forces with a Jedi Knight, a cocky pilot, a wookiee and two droids to
save the universe from the Empire's world-destroying battle-station, while also attempting to
rescue Princess Leia from the evil Darth Vader.",
"actors" : ["Mark Hamill","Harrison Ford","Carrie Fisher"],
"year" : 1977
}](https://image.slidesharecdn.com/elasticserach-190114171946/85/Elastic-serach-8-320.jpg)


![13
Les bases d’Elasticsearch
SGBDR ELASTICSEARCH
Base de données Index ES
Tables de la BD Indices de l’index ES
Colonnes de la table Types de l’indice /propriétés des
documents JSON
Lignes de la table Documents de l’indice
{
"title" : "Star Wars",
"directors" : ["George Lucas"],
"release_date" : "1977-05-25T00:00:00Z",
"rating" : 8.7,
"genres" : ["Action","Adventure","Fantasy","Sci-Fi"],
}](https://image.slidesharecdn.com/elasticserach-190114171946/85/Elastic-serach-13-320.jpg)




![ElasticSearch offre une API REST permettant d’effectuer tous
types d’opération. Il supporte les méthodes HTTP (GET, PUT,
POST et DELETE).
curl -XPUT 'http://localhost:9200/[index]/[type]/[id]/[action]'
Index : Nom de l’index
Type : Nom du type du document
Id : ID du document
Action : Action à effectuer
18
pratique](https://image.slidesharecdn.com/elasticserach-190114171946/85/Elastic-serach-18-320.jpg)

















![37
Les filtres
c'est sa capacité à pouvoir filtrer tous les types possibles de données:
d'extraire les données
d'analyser les données
de nettoyer les donnée
filter {
# Lecture d'un fichier csv
csv {
columns => ["col1","col2","col3"]
separator => ";"
}
}](https://image.slidesharecdn.com/elasticserach-190114171946/85/Elastic-serach-37-320.jpg)













































![[Breizhcamp 2015] MongoDB et Elastic, meilleurs ennemis ?](https://cdn.slidesharecdn.com/ss_thumbnails/mongodbetelasticmeilleursennemis-150612210744-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






