Téléchargé 32 fois















![Travailler avec des vecteurs
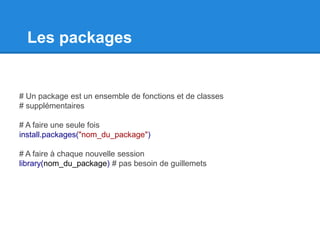
# Sélections
V1[1] # Sélectionne le premier élément
V1[c(1,2)] # Sélectionne les deux premiers éléments
V1[c(TRUE, TRUE, FALSE)] # Idem
V1[V1 < V2] # Que va-t-il se passer ?
V2[V1] # Et là ?
# Chaque élément d’un vecteur peut avoir un nom:
V3 <- c(a = 1, b = 2, c = 3)
V3
V3["a"]
V3[c("a", "b")]](https://image.slidesharecdn.com/rintro-130426075324-phpapp01/85/Une-Introduction-a-R-19-320.jpg)
![Travailler avec des « data.frame »
# Importer données : read.csv, read.xls, sqlQuery, load, etc.
data <- read.csv(«fichier.csv»)
# Afficher une variable
data$nom_de_variable
#Supprimer une variable:
data$var <- NULL
# Créer une variable
data$nouvelle_var <- data$var1 + 3
# Sélections : comme pour les vecteurs sauf qu’on a deux dimensions
data[c(1, 2, 3), ] # 3 premières lignes
data[, 1] # 1ère colonne
data[c(1, 2, 3), 1] # trois premiers éléments de la 1ère colonne
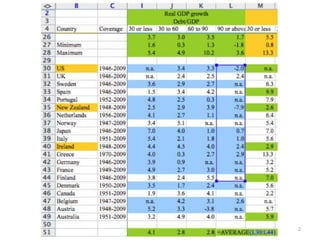
head(data, 3) # trois premières lignes du tableau
tail(data, 3) # trois dernières lignes du tableau](https://image.slidesharecdn.com/rintro-130426075324-phpapp01/85/Une-Introduction-a-R-20-320.jpg)



Le document présente une introduction à R, un logiciel d'analyse de données open source, mettant en avant ses avantages tels que sa simplicité, sa flexibilité et son interactivité. Il aborde la gestion des données, les types de données disponibles, les bases de la programmation en R, ainsi que des conseils pratiques pour obtenir de l'aide et installer des packages. Les utilisateurs sont également informés des inconvénients du logiciel, notamment en termes de gestion de la mémoire et de performance.










![Comprendre l’intelligence artificielle [webinaire]](https://cdn.slidesharecdn.com/ss_thumbnails/technologiawebinaireintelligenceartificielleclaudemarson01042019-190403213713-thumbnail.jpg?width=640&height=640&fit=bounds)






























































