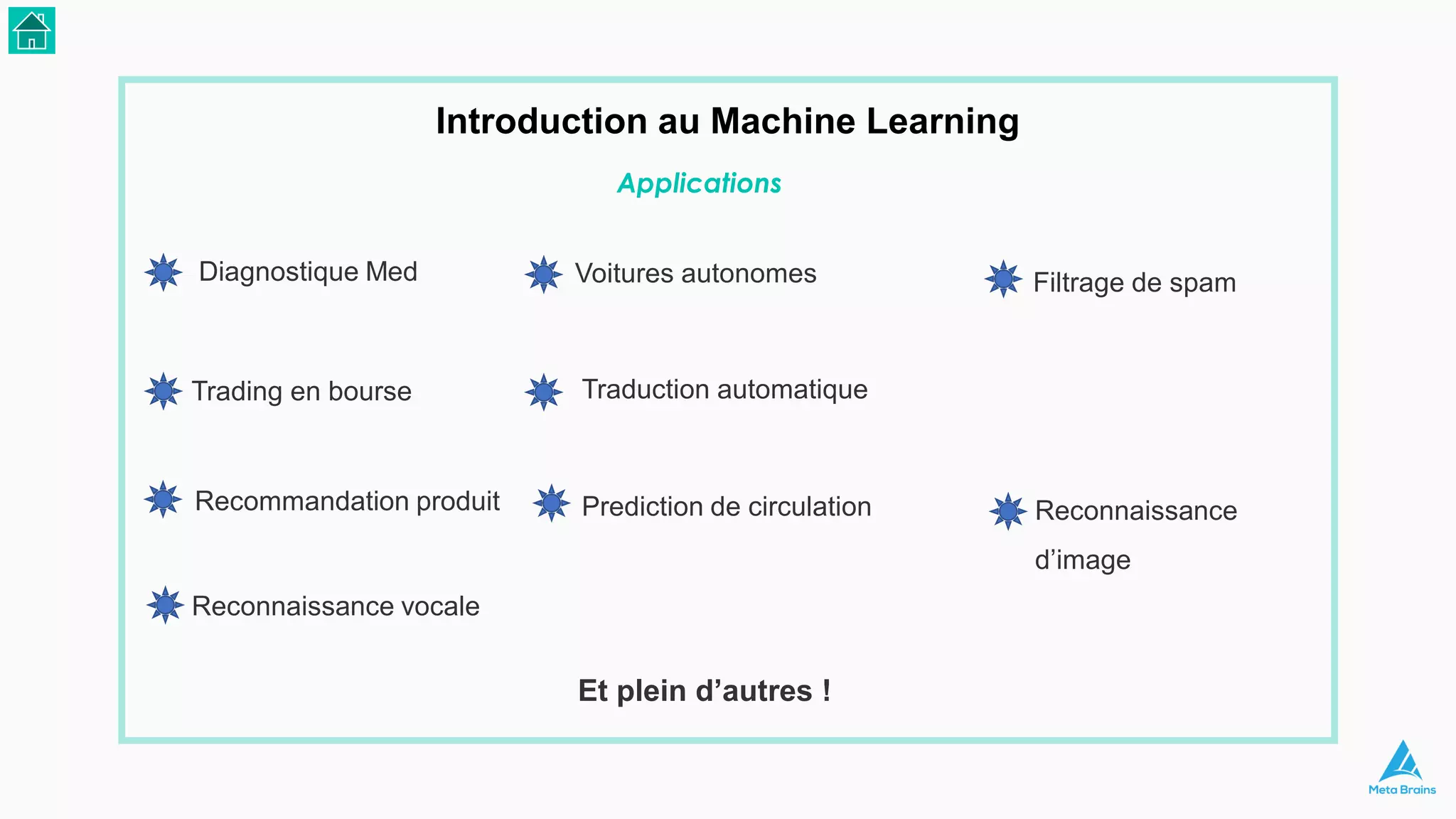
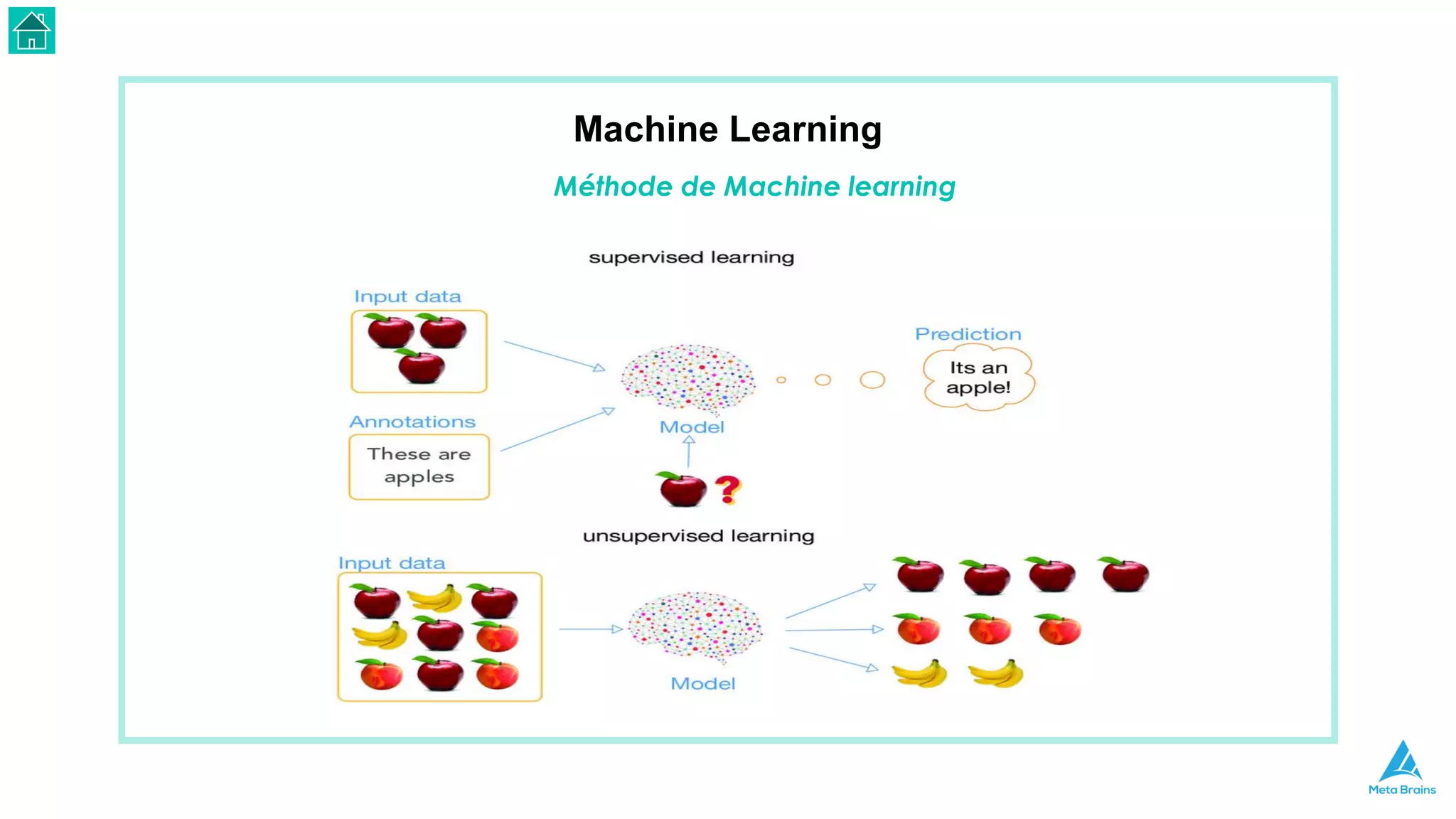
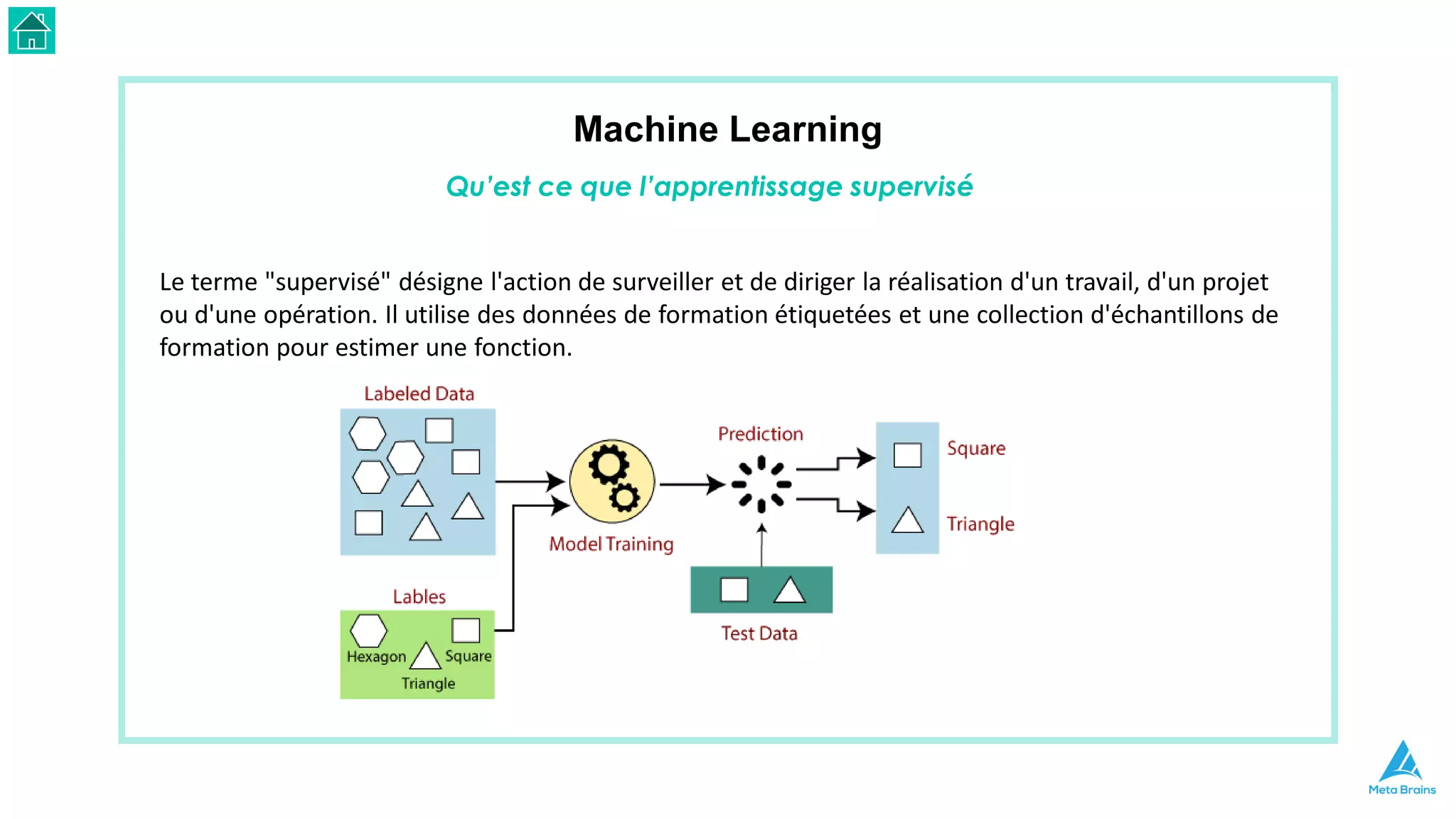
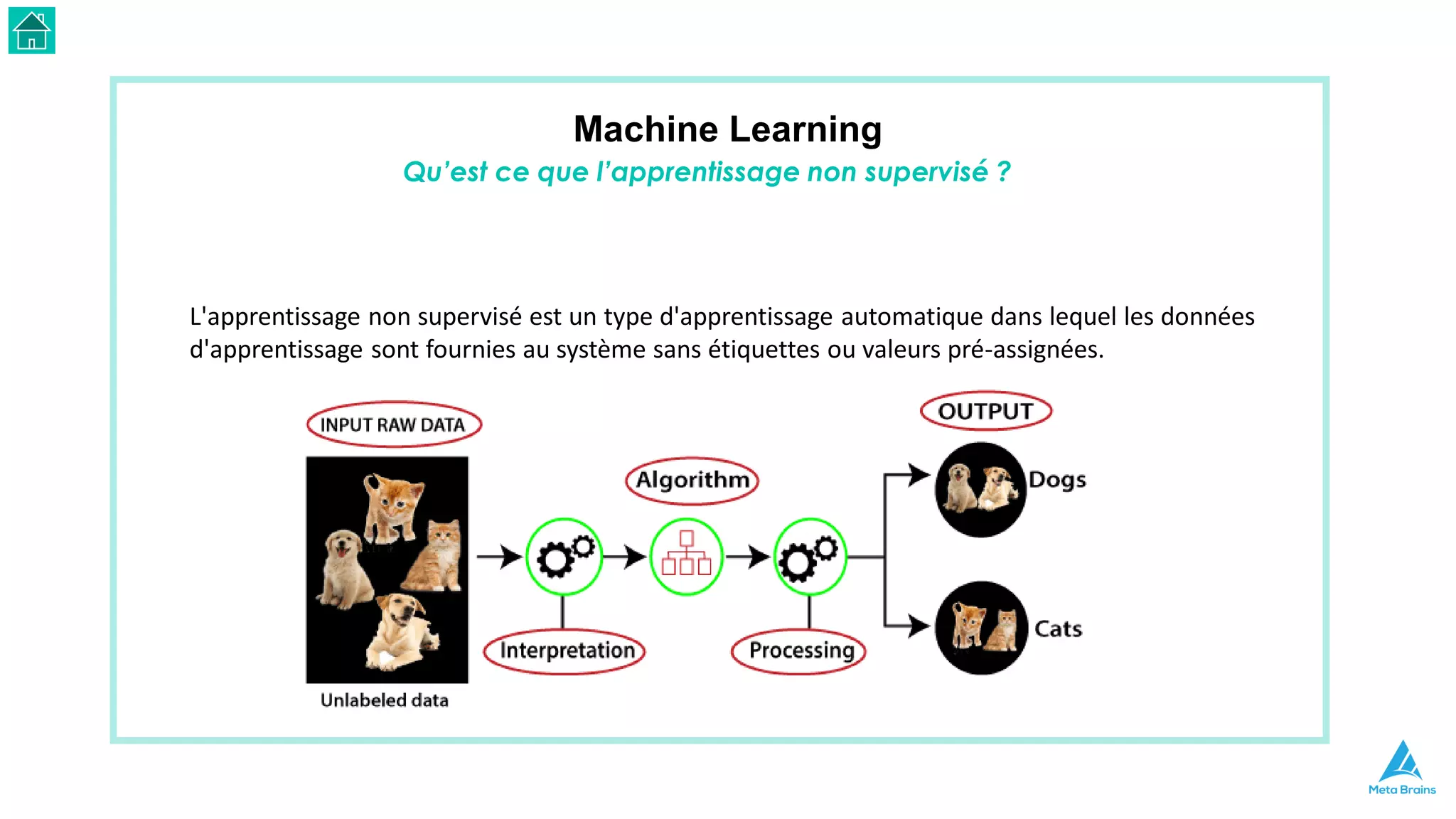
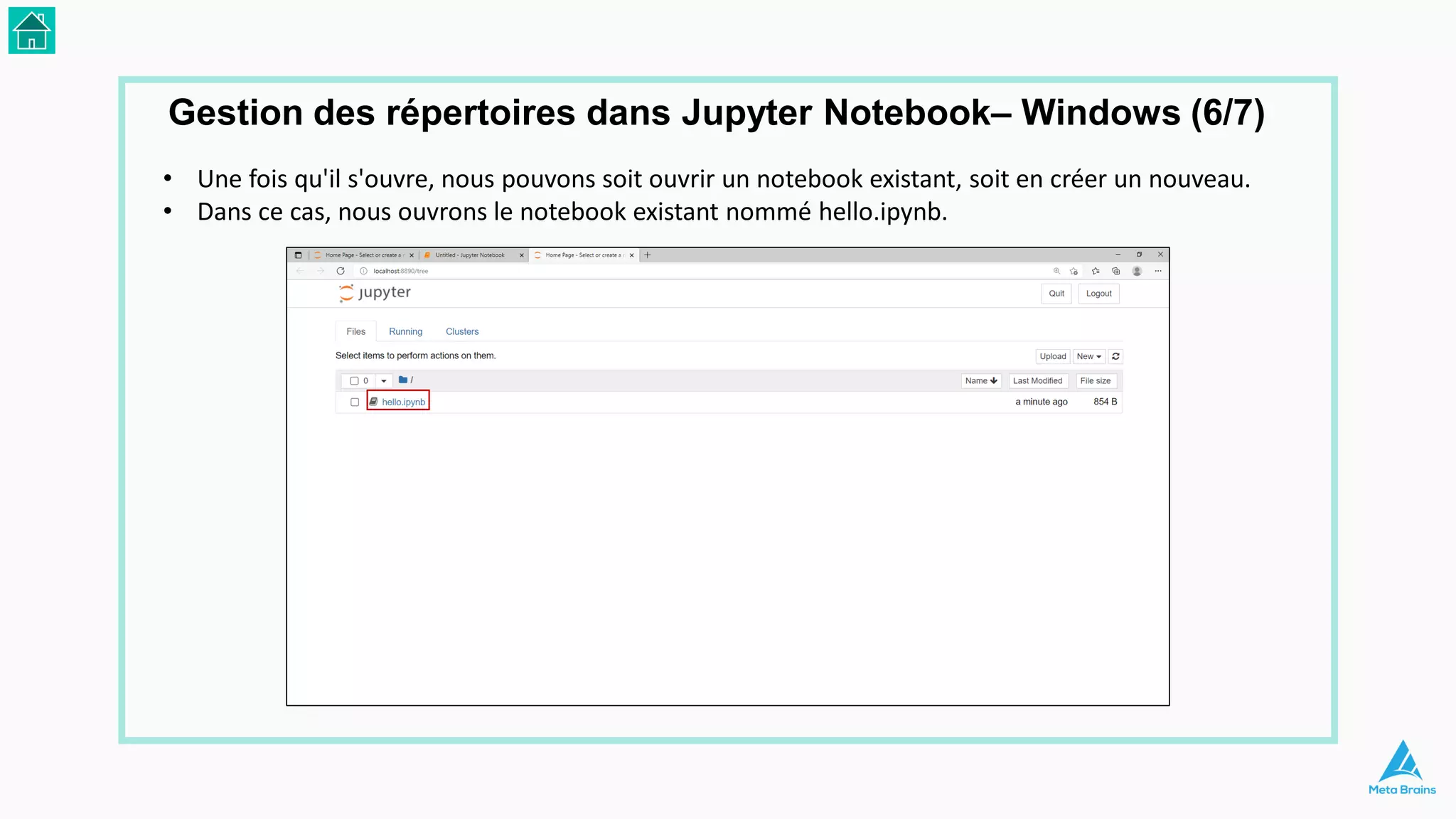
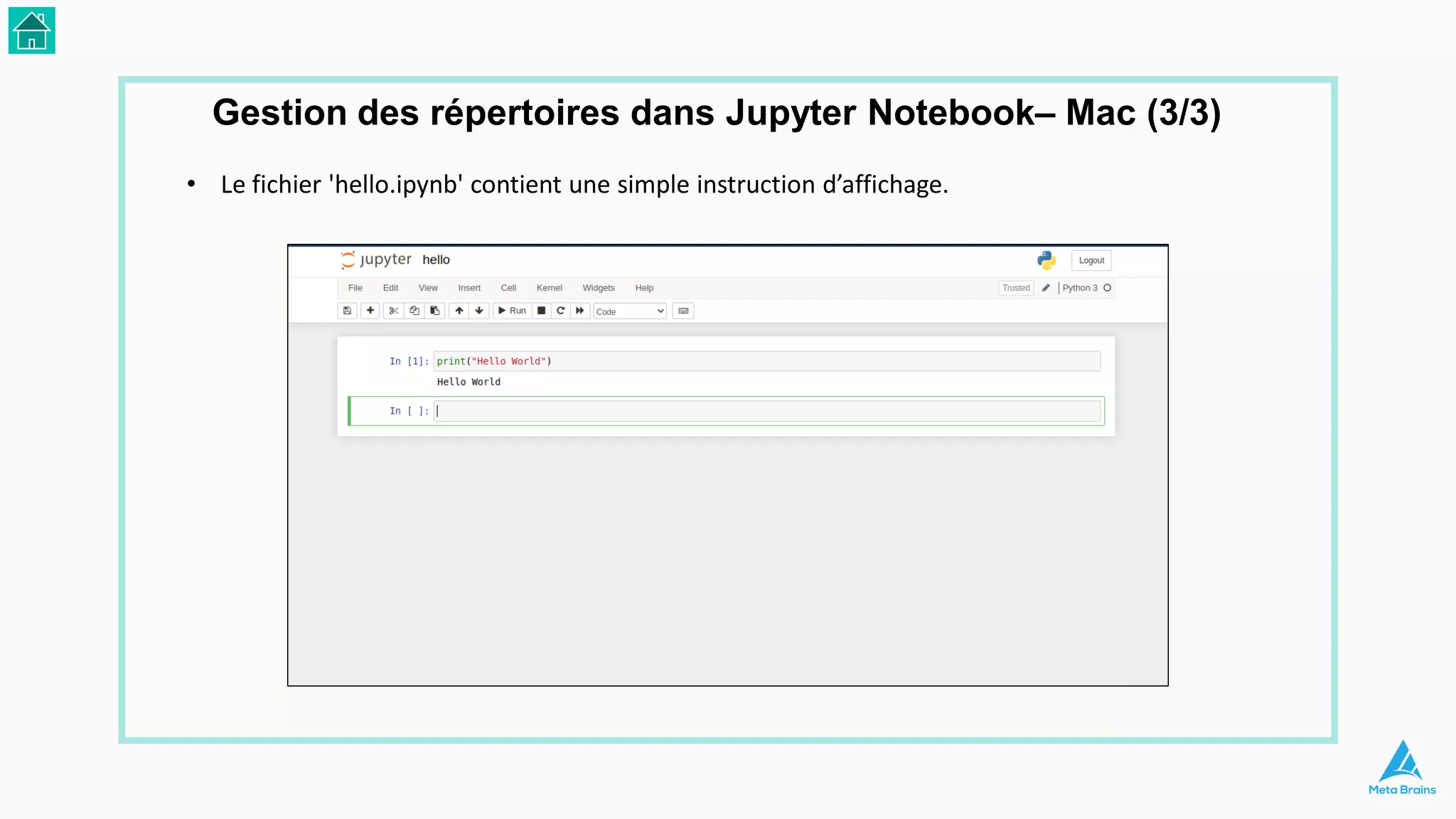
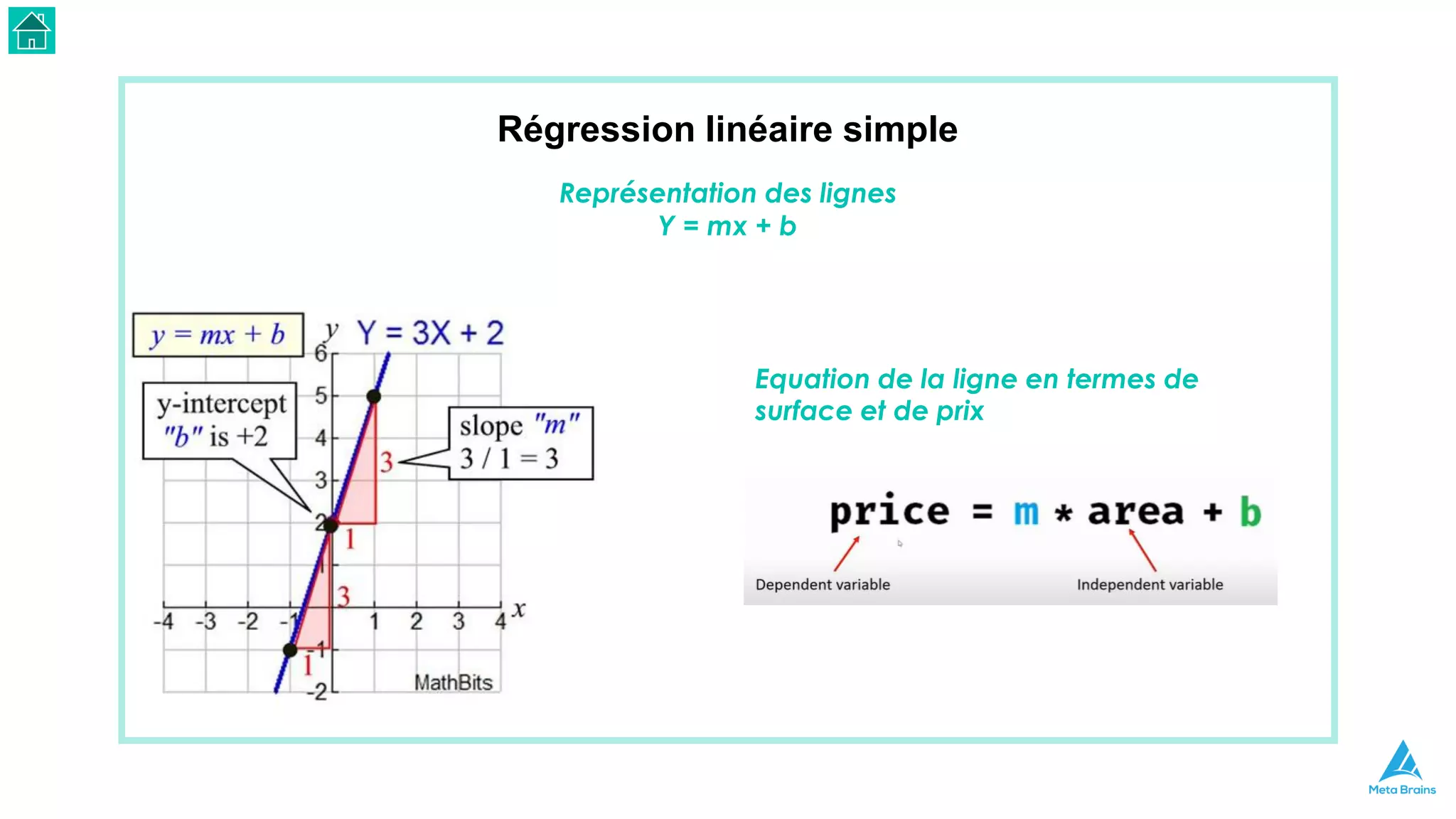
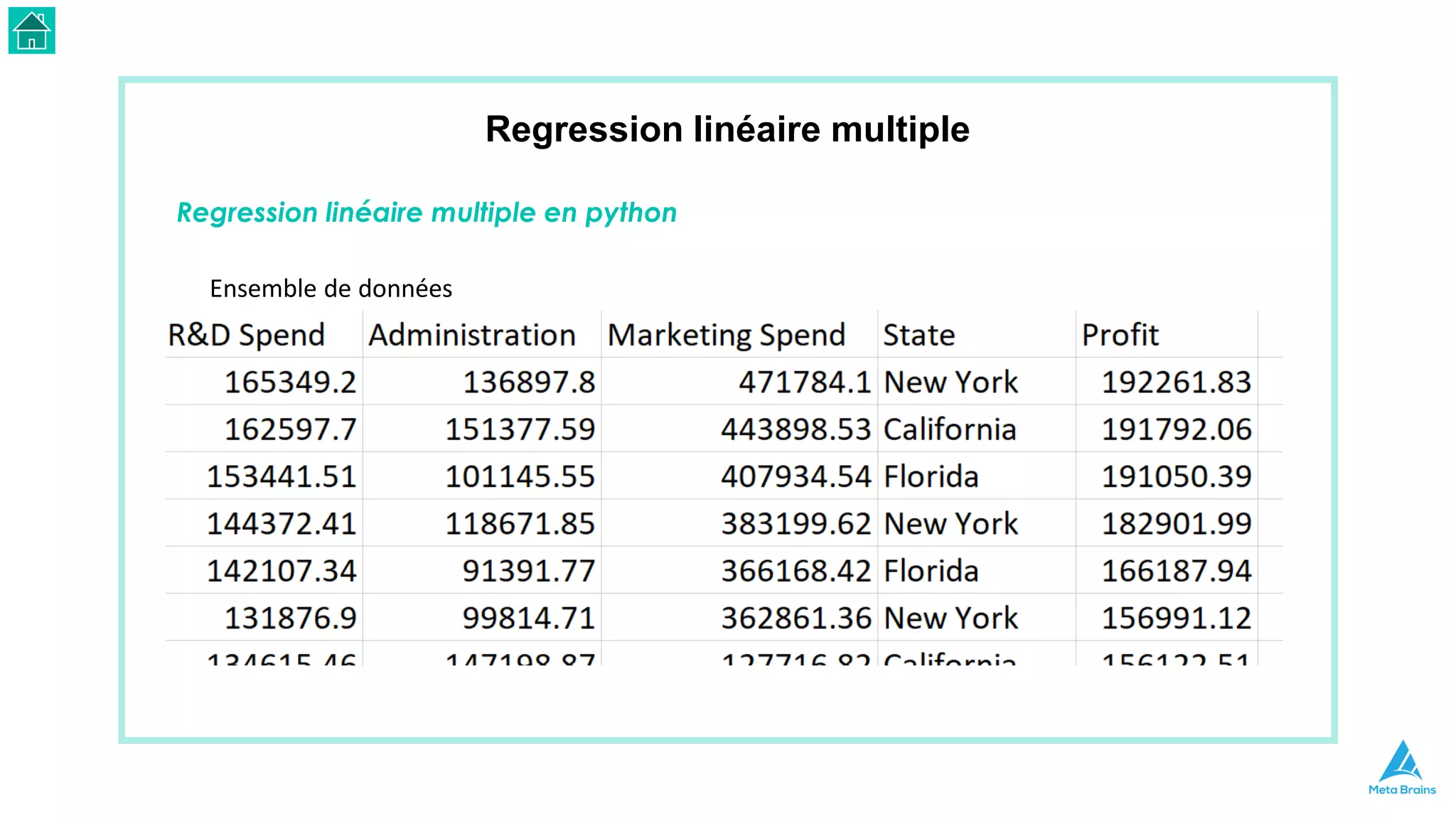
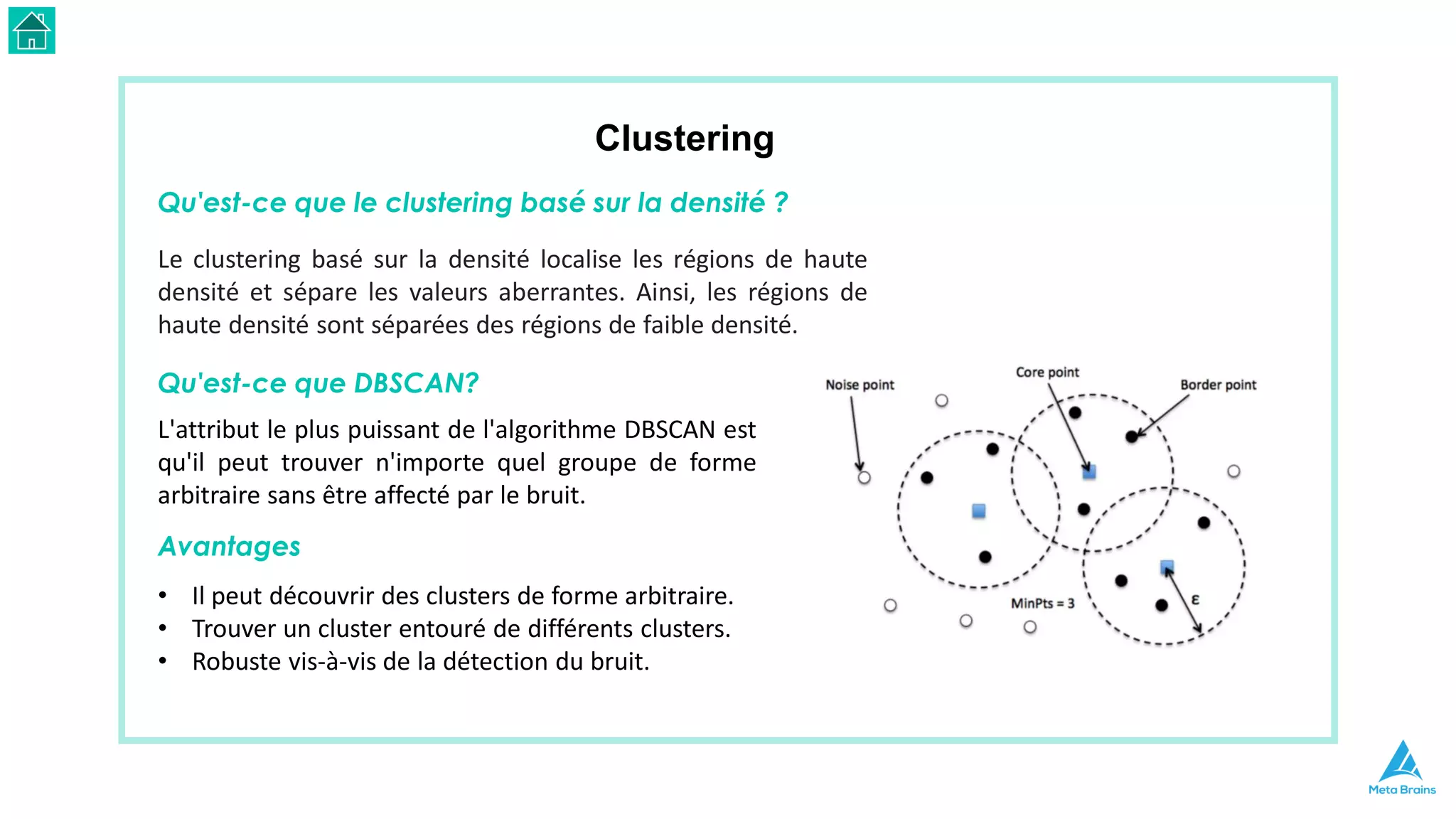
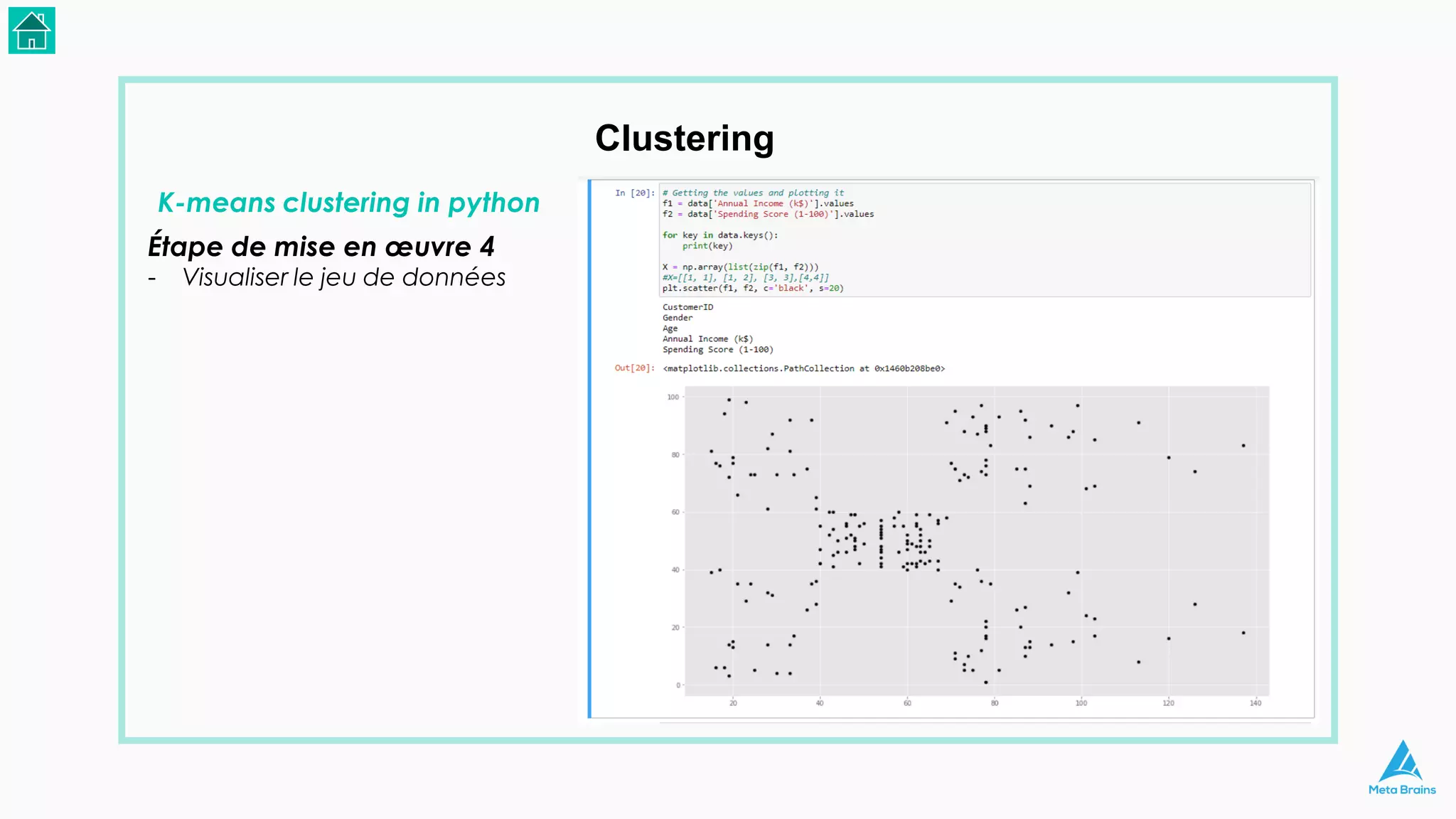
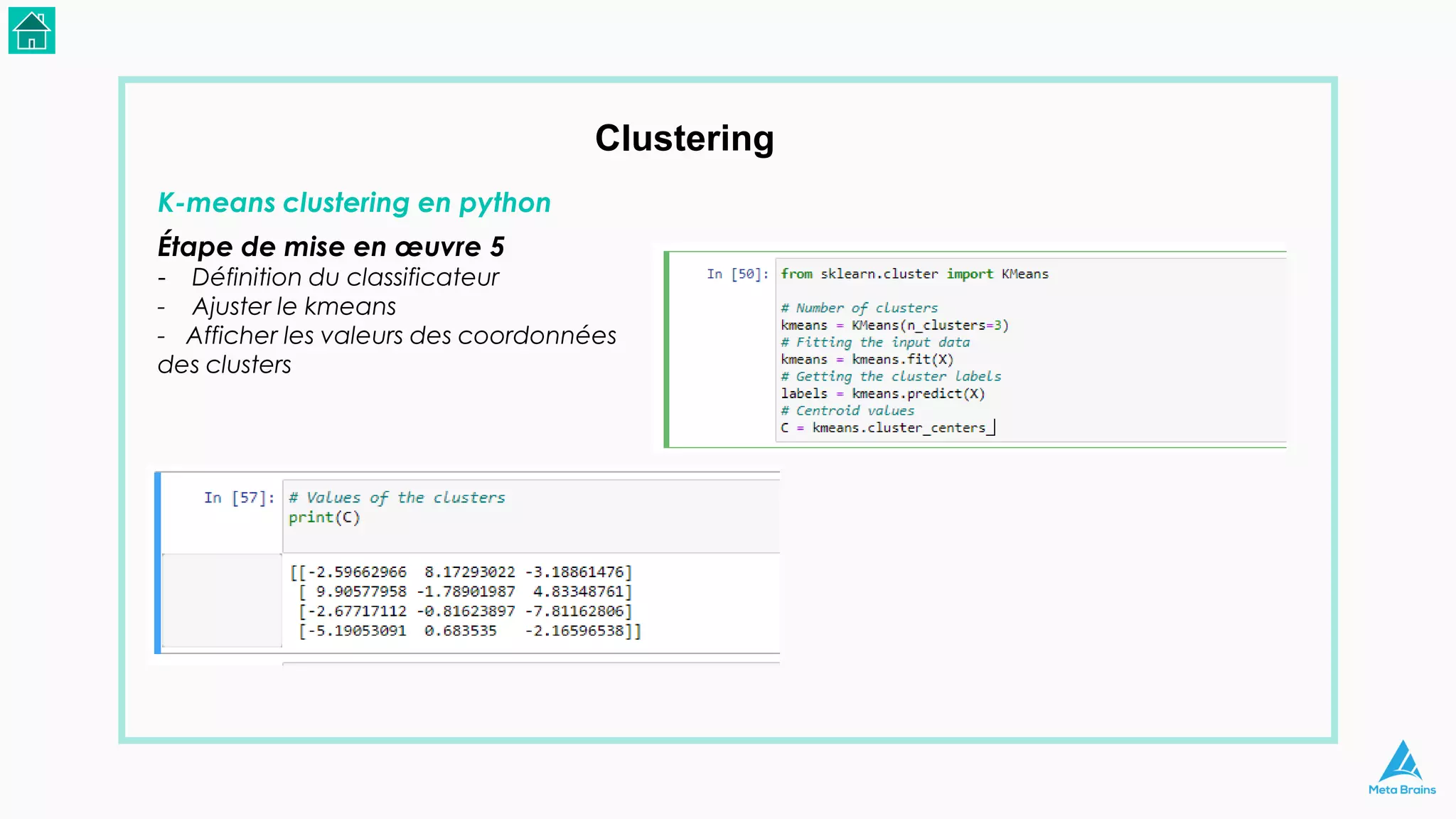
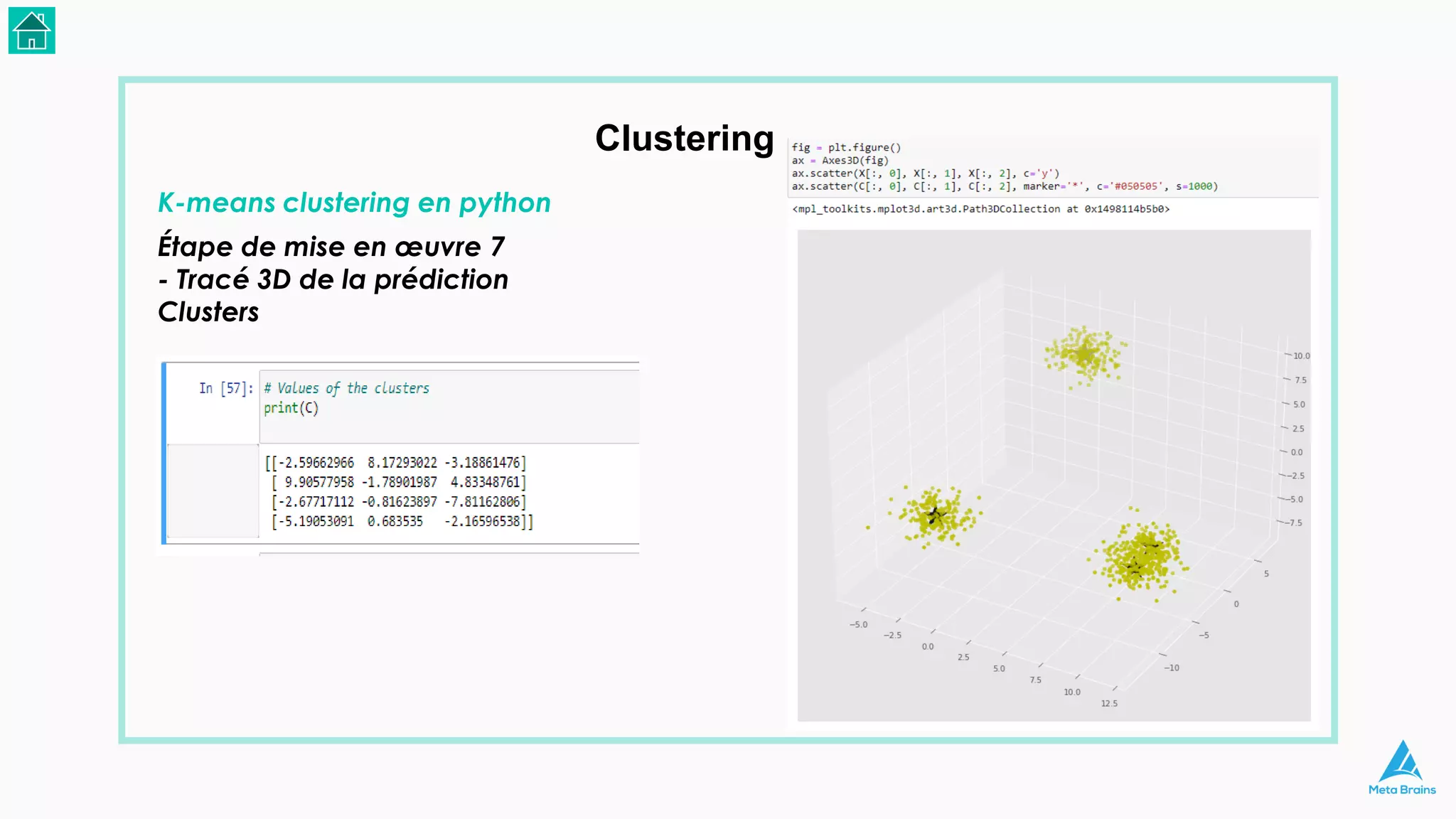
Le document présente une introduction au machine learning et son utilisation via Python, en détaillant divers algorithmes, tels que la régression linéaire et les méthodes de classification. Il aborde également les bibliothèques Python essentielles pour le machine learning, les différences entre l'apprentissage supervisé et non supervisé, ainsi que des instructions pour installer Python et Jupyter Notebook. Enfin, il met en lumière des applications pratiques du machine learning dans le monde réel.

































































































































































































![[GAV 2025] - Impactomètres viande de boeuf](https://cdn.slidesharecdn.com/ss_thumbnails/prsentationgav2025-impactomtresviandedeboeuf-p-251211161728-dea3d37d-thumbnail.jpg?width=640&height=640&fit=bounds)




